Python 10 : GESTION des STRINGS
L’utilisation de ce type d’outils va nous être utile pour aborder un autre thème courant en informatique : la cryptologie ou l’art de coder/décoder un message pour le rendre illisible et incompréhensible en cas d’interception.
Nous utiliserons pour votre premier vrai programme par fenêtre le classique pendu puis le codage rot13, avant de compliquer les choses dans la leçon suivante.
1 - Lecture d’éléments avec une boucle itérative nominative FOR
Nous avons vu dans l'activité précédente que le string est un ensemble ordonné de caractères et qu'on peut les lire un à un en utilisant une boucle FOR.
Si vous n'êtes pas familier avec le code ci-dessous, il vaut mieux repartir voir la partie sur le FOR dans les deux activités précédentes :
texte = "Bonjour !" # On crée le string texte
for caractere in texte : # Pour chaque caractère contenu dans texte
print(caractere) # Affiche caractere à l'écran
input("pause")
01° Sans lancer le code, répondre à la question suivante : Que devrait-on voir dans la console ?
Voir l'exécution :
texte :
caractere :
>>>
02° Lancer le code. Vérifiez ainsi si votre réponse précédente est bonne.
...CORRECTION ...
B
o
n
j
o
u
r
!
03° Quel est le numéro d'index de la première lettre du string, le B ? Comment obtenir ce B en utilisant la variable texte et cet index ?
...CORRECTION ...
B possède le numéro d'index 0 puisqu'on commence à numéroter à partir de 0.
Pour atteindre ce B, il faut utiliser les crochets : texte[0]
04° Combien de caractères possède cette chaîne de caractères ?
...CORRECTION ...
Elle possède 9 caractéres : B - o - n - j - o - u - r - ESPACE - !.
L'espace est donc un 'caractère' pour l'ordinateur.
Si les réponses vous semblent étranges, il serait mieux de repartir voir la partie FOR de l'activité précédente.
2 - Encodage ASCII des caractères
Nous allons profiter de ce cours pour faire un peu de cryptologie, mais nous devons d’abord comprendre comment l’ordinateur stocke les caractères qu’on lui envoie. Le principe est simple : l’ordinateur n’est qu’une machine à calculer, il ne sait stocker que des nombres.
Nous avons vu que lorsqu’il travaille sur une image, il gère des nombres.
De même, lorsqu’il travaille sur des lettres (des « caractères »), il gère des nombres. Ainsi, il faut décider par quel nombre coder A, B, a, b, 0, 8 …
Le codage basique des caractères est le codage ASCII (qui fut publié en 1963) : on associe à chaque caractère un nombre compris entre 0 et 127. On obtient donc 128 possibilités.
05° A votre avis, les caractères ASCII sont donc codés sur combien de bits puisque le code commence à 0 et finit à 127 ? On rappelle que si X est le nombre de bits, on obtient un nombre de possibilités de 2 à la puissance X, 2X.
Rappel : un octet correspond à 8 bits : M = 1010 1111 vaut M = 128 + 32 + 8 + 4 + 2 + 1 = 175. Vous pouvez aller revoir la leçon sur la gestion des images par Python si vous avez besoin d'un rappel plus conséquent. Avec 8 bits, on obtient un codage allant de 0 à 255, soit 256 possibilités.
...CORRECTION ...
Pour stocker 128 valeurs (allant de 0 à 127, n'oubliez pas qu'on commence à zéro), il faut 7 bits.
En effet, 27 vaut 128.
A l'époque, la mémoire était une denrée rare et on ne stockait même pas les caractères sur un octet (8 bits) !
ASCII se prononce “ASKI” pour American Standard Code for Information Interchange : il s’agit d’une norme d’encodage informatique des caractères alphanumériques standards de l’alphabet et de quelques « caractères » spéciaux permettant à l’ordinateur de comprendre qu’on veut faire une tabulation, un saut à la ligne …
Revoilà l’exemple typique du "Hello World" qui donnerait :
| Contenu de la mémoire | A l’écran | Valeur codante | en binaire |
|---|---|---|---|
| Start of Text | 2 | 000 0010 | |
| H | H | 72 | 100 1000 |
| e | e | 101 | 110 0101 |
| l | l | 108 | 110 1100 |
| l | l | 108 | 110 1100 |
| o | o | 111 | 110 1111 |
| Space | 32 | 010 0000 | |
| W | W | 87 | 101 0111 |
| o | o | 111 | 110 1111 |
| r | r | 114 | 111 0010 |
| l | l | 108 | 110 1100 |
| d | d | 100 | 110 0100 |
| End of Text | 3 | 000 0011 |
On remarquera qu’on code également des “caractères” qui ne sont pas imprimés à l’écran : il s’agit de caractères de contrôle du flux en grande majorité : on peut savoir quand un texte commence, quand il est fini, quand on doit partir à la ligne, faire une tabulation … En gros, certains caractères sont faits pour être affichés, d’autres pour savoir comment on affiche.
Si vous voulez regarder la correspondance du tableau avec le code, taper votre caractère ci-dessous :
Le caractère est codé par
La prochaine fois que vous lirez 000 0010 100 1000 110 0101 110 1100 ... vous devriez maintenant un peu mieux comprendre votre ordinateur...
Et voilà la fameuse table de correspondance ASCII :
Les premiers de la liste sont des caractères de contrôle et de gestion :
| Type | Décimal | Symbole | Signification | Binaire |
|---|---|---|---|---|
| Contrôle | 0 | NULL or NUL | Null | 000 0000 |
| Contrôle | 1 | SOM or SOH | Start of Heading | 000 0001 |
| Contrôle | 2 | EOA or STX | Start of Text | 000 0010 |
| Contrôle | 3 | EOM or ETX | End of Text | 000 0011 |
| Contrôle | 4 | EOT | End of Transmission | 000 0100 |
| Contrôle | 5 | WRU or ENQ | Enquiry | 000 0101 |
| Contrôle | 6 | RU or ACK | Acknowledgement | 000 0110 |
| Contrôle | 7 | BELL or BEL | Bell | 000 0111 |
| Contrôle | 8 | FE0 or BS | Backspace | 000 1000 |
| Contrôle | 9 | HT/SK or HT | Horizontal Tab | 000 1001 |
| Contrôle | 10 | LF | Line Feed | 000 1010 |
| Contrôle | 11 | VTAB or VT | Vertical Tab | 000 1011 |
| Contrôle | 12 | FF | Form Feed | 000 1100 |
| Contrôle | 13 | CR | Carriage Return | 000 1101 |
| Contrôle | 14 | SO | Shift Out | 000 1110 |
| Contrôle | 15 | SI | Shift In | 000 1111 |
| Contrôle | 16 | DC0 or DLE | Data Link Escape | 001 0000 |
| Contrôle | 17 | DC1 | Device Control 1 | 001 0001 |
| Contrôle | 18 | DC2 | Device Control 2 | 001 0010 |
| Contrôle | 19 | DC3 | Device Control 3 | 001 0011 |
| Contrôle | 20 | DC4 | Device Control 4 | 001 0100 |
| Contrôle | 21 | ERR or NAK | Negative Acknowledgement | 001 0101 |
| Contrôle | 22 | SYNC or SYN | Synchronous Idle | 001 0110 |
| Contrôle | 23 | LEM or ETB | End of Transmission Block | 001 0111 |
| Contrôle | 24 | S0 or CAN | Cancel | 001 1000 |
| Contrôle | 25 | S1 or EM | End of Medium | 001 1001 |
| Contrôle | 26 | S2 or SS | Substitute | 001 1010 |
| Contrôle | 27 | S3 or ESC | Escape | 001 1011 |
| Contrôle | 28 | S4 or FS | File Separator | 001 1100 |
| Contrôle | 29 | S5 or GS | Group Separator | 001 1101 |
| Contrôle | 30 | S6 or RS | Record Separator | 001 1110 |
| Contrôle | 31 | S7 or US | Unit Separator | 001 1111 |
Et à partir de 32, on trouve les caractères dits imprimables car visibles à l'écran :
| Type | Décimal | Symbole | Signification | Binaire |
|---|---|---|---|---|
| Printable | 32 | (space) | (space) | 010 0000 |
L'espace est un caractère un peu spécial mais les autres sont visibles :
| Type | Décimal | Symbole | Binaire |
|---|---|---|---|
| Printable | 33 | ! | 010 0001 |
| Printable | 34 | " | 010 0010 |
| Printable | 35 | # | 010 0011 |
| Printable | 36 | $ | 010 0100 |
| Printable | 37 | % | 010 0101 |
| Printable | 38 | & | 010 0110 |
| Printable | 39 | ' | 010 0111 |
| Printable | 40 | ( | 010 1000 |
| Printable | 41 | ) | 010 1001 |
| Printable | 42 | * | 010 1010 |
| Printable | 43 | + | 010 1011 |
| Printable | 44 | , | 010 1100 |
| Printable | 45 | - | 010 1101 |
| Printable | 46 | . | 010 1110 |
| Printable | 47 | / | 010 1111 |
| Printable | 48 | 0 | 011 0000 |
| Printable | 49 | 1 | 011 0001 |
| Printable | 50 | 2 | 011 0010 |
| Printable | 51 | 3 | 011 0011 |
| Printable | 52 | 4 | 011 0100 |
| Printable | 53 | 5 | 011 0101 |
| Printable | 54 | 6 | 011 0110 |
| Printable | 55 | 7 | 011 0111 |
| Printable | 56 | 8 | 011 1000 |
| Printable | 57 | 9 | 011 1001 |
| Printable | 58 | : | 011 1010 |
| Printable | 59 | ; | 011 1011 |
| Printable | 60 | < | 011 1100 |
| Printable | 61 | = | 011 1101 |
| Printable | 62 | > | 011 1110 |
| Printable | 63 | ? | 011 1111 |
| Printable | 64 | @ | 100 0000 |
| Printable | 65 | A | 100 0001 |
| Printable | 66 | B | 100 0010 |
| Printable | 67 | C | 100 0011 |
| Printable | 68 | D | 100 0100 |
| Printable | 69 | E | 100 0101 |
| Printable | 70 | F | 100 0110 |
| Printable | 71 | G | 100 0111 |
| Printable | 72 | H | 100 1000 |
| Printable | 73 | I | 100 1001 |
| Printable | 74 | J | 100 1010 |
| Printable | 75 | K | 100 1011 |
| Printable | 76 | L | 100 1100 |
| Printable | 77 | M | 100 1101 |
| Printable | 78 | N | 100 1110 |
| Printable | 79 | O | 100 1111 |
| Printable | 80 | P | 101 0000 |
| Printable | 81 | Q | 101 0001 |
| Printable | 82 | R | 101 0010 |
| Printable | 83 | S | 101 0011 |
| Printable | 84 | T | 101 0100 |
| Printable | 85 | U | 101 0101 |
| Printable | 86 | V | 101 0110 |
| Printable | 87 | W | 101 0111 |
| Printable | 88 | X | 101 1000 |
| Printable | 89 | Y | 101 1001 |
| Printable | 90 | Z | 101 1010 |
| Printable | 91 | [ | 101 1011 |
| Printable | 92 | \ | 101 1100 |
| Printable | 93 | ] | 101 1101 |
| Printable | 94 | ^ | 101 1110 |
| Printable | 95 | _ | 101 1111 |
| Printable | 96 | ` | 110 0000 |
| Printable | 97 | a | 110 0001 |
| Printable | 98 | b | 110 0010 |
| Printable | 99 | c | 110 0011 |
| Printable | 100 | d | 110 0100 |
| Printable | 101 | e | 110 0101 |
| Printable | 102 | f | 110 0110 |
| Printable | 103 | g | 110 0111 |
| Printable | 104 | h | 110 1000 |
| Printable | 105 | i | 110 1001 |
| Printable | 106 | j | 110 1010 |
| Printable | 107 | k | 110 1011 |
| Printable | 108 | l | 110 1100 |
| Printable | 109 | m | 110 1101 |
| Printable | 110 | n | 110 1110 |
| Printable | 111 | o | 110 1111 |
| Printable | 112 | p | 111 0000 |
| Printable | 113 | q | 111 0001 |
| Printable | 114 | r | 111 0010 |
| Printable | 115 | s | 111 0011 |
| Printable | 116 | t | 111 0100 |
| Printable | 117 | u | 111 0101 |
| Printable | 118 | v | 111 0110 |
| Printable | 119 | w | 111 0111 |
| Printable | 120 | x | 111 1000 |
| Printable | 121 | y | 111 1001 |
| Printable | 122 | z | 111 1010 |
| Printable | 123 | { | 111 1011 |
| Printable | 124 | | | 111 1100 |
| Printable | 125 | } | 111 1101 |
| Printable | 126 | ~ | 111 1110 |
Le numéro 127 correspond à la touche DEL d'effacement :
| Type | Décimal | Symbole | Signification | Binaire |
|---|---|---|---|---|
| Contrôle | 127 | DEL | 111 1111 |
Pour connaître le code d’un caractère, on peut utiliser une fonction native (integrée de base dans Python) qui s’applique sur des variables caractere contenant un caractère : ord(caractere). La fonction renvoie un nombre base 10 (décimal) qui correspond à la valeur encodée par le caractère caractere.
Exemple :
caractere = input("Donner un caractere et un seul : ")
print(ord(caractere))
caractere = input("Un autre : ")
print(ord(caractere))
input("pause")
06° Tester le code ci-dessus sur plusieurs caractères ASCII.
07° Et si vous tentiez une lecture automatisée du codage ? Utiliser un input pour stocker une chaîne de caractères et utiliser ensuite un for pour afficher le code de chaque caractère un à un. Vérifiez du coup si je ne me suis pas trompé avec « Hello World» : 72 101 108 108 111 32 87 111 114 108 100.
Voilà de quoi tester les réponses de votre code :
Votre texte :
Codes des caractères du texte :
08° Avez-vous été curieux ? Tenter de lancer une chaîne de caractères qui contient des caractères bizarres pour nos amis anglo-saxons ? Des é, â et autres ç. Regardez bien la valeur affichée. Mais, mais …ça ne dépasserait pas 127 cette histoire ?
Pour l’instant, nous allons nous limiter au cas 0 à 127 avec de l’ASCII pur. Et nous compliquerons les choses ensuite. Il s'agit des encodages dits ASCII étendu (sur 1 octet) ou des encodages modernes comme l'UTF-8 qui permet d'utiliser une sorte de code universel qu'on nomme UNICODE.
Précision sur le résultat de ord(x) :
Unicode
Le code renvoyé par ord n'est pas vraiment le "code ASCII" du caractère, même si la valeur est la bonne, soyez rassuré.
Nous avons vu que ord parvient à donner le code de caractères qui ne sont pas dans la table ASCII, ceux supérieurs à 127.
Sachez que ord(x) renvoie en réalité la valeur UNICODE du caractère. Il se trouve que les codes ASCII et les codes UNICODE sont les mêmes sur la plage 0-127. C'est volontaire : UNICODE a été établi avec comme contrainte d'être compatible avec la vielle norme ASCII.
Rappel : Dans l'une des activités précédentes, nous avions vu la fonction inverse de ord : chr(x) qui renvoie le caractère codé par la valeur x.
>>> chr(65)
A
>>> ord('A')
65
3 - Le string est non mutable on vous dit !
Créer une chaîne de caractères, c’est facile sous Python :
- On peut faire de l’affectation directe :
monTexte = "Hello World !" - On peut rajouter des éléments un à un :
monTexte = "Hello" + " World" + "!".
09° Lancer le code ci-dessous qui vous montre les deux façons de créer une chaîne contenant « Hello World ! ».
print("Creation de monTexte en une étape")
monTexte = "Hello Wordl!" # On crée le string
print(monTexte)
print("Création de monTexte en plusieurs étapes")
monTexte = "Hello"
print(monTexte)
monTexte = monTexte + " World"
print(monTexte)
monTexte = monTexte + "!"
print(monTexte)
input("pause")
Les éléments d’une chaîne de caractères Python ont une spécificité : on ne peut pas les modifier une fois créées. Mais, enfin … Et une méthode telle que replace ?
monTexte.replace("a","*")
Elle va bien remplacer tous les a par des * non ?
Non, cette fonction renvoie simplement une copie de la première chaîne en ayant changé les caractères demandés. D’ailleurs, on doit l'utiliser ainsi pour parvenir à changer monTexte :
monTexte = monTexte.replace("a","*")
On remplace donc intégralement l’ancienne variable monTexte par une nouvelle monTexte. Nous n’avons pas juste changé un caractère par ci, un caractère par là.
10° Lancer le code ci-dessous pour vous convaincre que la modification modifie également l'id, la réference interne.
monTexte = "Bonjour"
print('ID ',id(monTexte), '\t', monTexte)
monTexte = monTexte.replace('o','*')
print('ID ', id(monTexte), '\t', monTexte)
...CORRECTION ...
On obtient ceci :
ID 2446382005136 Bonjour
ID 2446382005248 B*nj*ur
On voit bien que la variable a été modifiée mais que son identifiant été modifiée également.
Oui, bon ... Ca change d'identification et alors ? C'est grave ?
Ca dépend. Si vous voulez que les modifications soient suivies oui.
Regardons le programme suivant :
monTexte1 = "Lait"
monTexte2 = "Carottes"
maListe = [ monTexte1,monTexte2 ]
print(maListe)
print(id(maListe[0]), '-', id(maListe[1]) )
monTexte2 = "Des Chips !"
print(maListe)
print(id(maListe[0]), '-', id(maListe[1]) )
En gros, on crée une liste à partir de deux variables monTexte et monTexte2. On affiche la liste et les id de ses éléments d'index 0 et 1.
['Lait', 'Carottes']
80144 - 27024
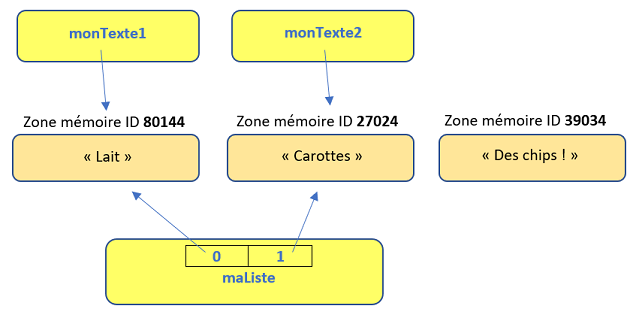
On modifie ensuite la variable monTexte2. On affiche la liste et les id de ses éléments.
['Lait', 'Carottes']
80144 - 27024
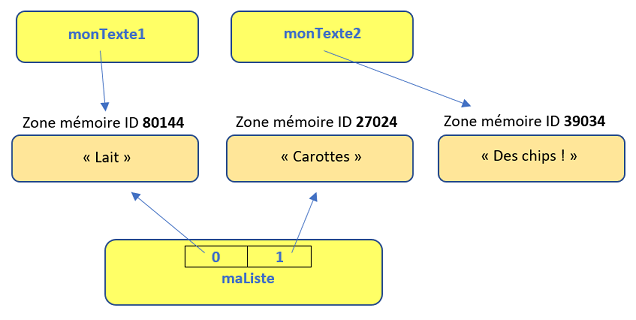
Comme vous pouvez le constater, la liste n'est pas modifiée : ses éléments pointent toujours vers l'ancien identifiant-mémoire.
11° Lancer le code ci-dessous pour vous convaincre (encore plus) que la modification directe d'un string ne fonctionne pas. C'est normal, souvenez-vous le string est non modifiable après création. On dira également que le string est non mutable.
monTexte = "Hello Wordl!" # On crée le string
monTexte[0] = "h" #Ceci, ça ne fonctionne pas !
print (monTexte)
input("pause")
Et oui, ça ne fonctionne pas. Pas de surprise, si ?
Conclusion : on dit que le String est non mutable. On ne peut pas modifier son contenu une fois créé. Pour avoir l'impression de modifier des données non mutables, il faut remplacer sa variable par une variable qui porte le même nom mais qui n'aura pas la même référence interne.
4 - "Modifier" un string - Le jeu du pendu
Bilan de la partie précédente : la seule façon de "modifier" un string (qui est non mutable), c'est de recréer un string qui porte le même nom.
Un exemple concret :
Voilà deux façons de "modifier" une chaîne de caractères de façon à remplacer chaque caractère par trois fois le même caractère. Ainsi :
maChaine = "Hello World!"
doit devenir
maChaine = *HHHeeellllllooo WWWooorrrlllddd"
La première version est élaborée avec la boucle for nominative qui énumère les caractères un par un.
monTexte = "Hello Wordl!"
temporaire = "" # On crée une chaine vide temporaire
for caractere in monTexte : # Pour chaque caractère de monTexte
temporaire = temporaire + 3*caractere # On rajoute trois fois le caractère
monTexte = temporaire # On remplace l'ancien monTexte
print(monTexte)
input("pause")
La seconde fonctionne avec un itérateur index qui lit les cases de la n°0 à la dernière.
monTexte = "Hello Wordl!"
longueur = len(monTexte)
temporaire = "" # On crée une chaine vide
for index in range(0,longueur) :
temporaire = temporaire + 3*monTexte[index]
monTexte = temporaire # On remplace l'ancien monTexte
print(monTexte) # On affiche le contenu
input("pause")
Voilà, vous savez maintenant comment modifier n’importe quel caractère d’une chaîne de caractères: il faut recréer une nouvelle chaîne portant le même nom !
Nous allons maintenant reprendre notre exercice du pendu que nous avions commencé dans l'une des activités précédentes.
12° Modifier le code ci-dessous pour "créer" une variable motTrouve à partir de motSecret : on doit remplacer les caractères par des étoiles, sauf s'il s'agit d'un tiret ou d'un espace. Pour l'instant, nous n'avons qu'un affichage.
#!/usr/bin/env python
# -*-coding:Utf-8 -*
motSecret = input("Tapez votre string secret : ") # On demande motSecret
# Création du string de réponse trouvée
motTrouve = ""
for element in motSecret : # Pour chaque caractère-element contenu dans trucSecret
if (element !=' ' and element !='-') :
print('*', end="") # Affiche * à l'écran
else :
print(element, end="") # Affiche element à l'écran
print()
input("pause")
Le résultat attendu si on demande d'afficher motSecret et motTrouve à la fin :
>>> Tapez votre string secret : Bonjour tout le monde
Bonjour tout le monde
******* **** ** *****
...CORRECTION ...
#!/usr/bin/env python
# -*-coding:Utf-8 -*
motSecret = input("Tapez votre string secret : ") # On demande motSecret
# Création du string de réponse trouvée
motTrouve = ""
for element in motSecret : # Pour chaque caractère-element contenu dans trucSecret
if (element !=' ' and element !='-') :
motTrouve = motTrouve + '*' # Rajoute *
else :
motTrouve = motTrouve + element # Rajoute element (espace ou tiret)
print(motSecret)
print(motTrouve)
input("pause")
Nous avions ensuite créer une boucle while infinie car nous ne pouvions pas faire évoluer notre réponse. Maintenant que la réponse trouvée est stockée dans le string motTrouve, nous allons pouvoir le changer au fur et à mesure de la découverte des lettres.
Par contre, nous allons devoir cette fois utiliser une boucle FOR numérique car nous avons besoin de connaitre ce qui se trouve à une position-index donnée dans motSecret et dans motTrouve.
Exemple :
>>> Tapez votre string secret : Bonjour tout le monde
Bonjour tout le monde
******* **** ** *****
>>> Tapez la lettre à tester : o
*o**o** *o** ** *o***
>>> Tapez la lettre à tester : e
*o**o** *o** *e *o**e
L'algorithme est donc quelque chose du genre :
- Stocker la lettre à tester dans la variable laLettre (fait dans le code ci-dessous)
- Créer une variable motTemporaire vide (fait)
- Pour chaque index de la variable motTrouve : (code bouclage fait)
- Si l' index de motSecret contient laLettre : concatener motSecret[ index ] dans motTemporaire (à faire)
- Sinon : concatener motTrouve[ index ] dans motTemporaire (à faire)
- Stocker motTemporaire dans motTrouve (à faire).
13° Remplacer pass dans le code suivant de façon à obtenir la mise à jour de la chaine motTrouve.
#!/usr/bin/env python
# -*-coding:Utf-8 -*
motSecret = input("Tapez votre string secret : ") # On demande motSecret
# Création du string de réponse trouvée
motTrouve = ""
for element in motSecret : # Pour chaque caractère-element contenu dans trucSecret
if (element !=' ' and element !='-') :
motTrouve = motTrouve + '*' # Rajoute *
else :
motTrouve = motTrouve + element # Rajoute element (espace ou tiret)
# Boucle du jeu
while True :
laLettre = input("Tapez la lettre à tester : ")
# Création de motTemporaire pour mettre motTrouve a jour
motTemporaire = ""
for index in range(len(motSecret)) : # Pour chaque caractère-element contenu dans trucSecret
pass
print(motTrouve)
input("pause")
...CORRECTION ...
#!/usr/bin/env python
# -*-coding:Utf-8 -*
motSecret = input("Tapez votre string secret : ") # On demande motSecret
# Création du string de réponse trouvée
motTrouve = ""
for element in motSecret : # Pour chaque caractère-element contenu dans trucSecret
if (element !=' ' and element !='-') :
motTrouve = motTrouve + '*' # Rajoute *
else :
motTrouve = motTrouve + element # Rajoute element (espace ou tiret)
# Boucle du jeu
while True :
laLettre = input("Tapez la lettre à tester : ")
# Création de motTemporaire pour mettre motTrouve a jour
motTemporaire = ""
for index in range(len(motSecret)) : # Pour chaque caractère-element contenu dans trucSecret
if ( motSecret[index] == laLettre ) :
motTemporaire = motTemporaire + motSecret[ index ]
else :
motTemporaire = motTemporaire + motTrouve[ index ]
motTrouve = motTemporaire
print(motTrouve)
input("pause")
Amélioration :
On remarquera qu'on crée la nouvelle string même si au final on ne modifera rien. Par exemple, si w n'est pas présent, on devra néanmoins créer la nouvelle chaine... On peut faire mieux en testant la présence ou non de w dans motSecret avec le mot-clé in : on effectuera les modifications que SI la lettre à tester est bien présente.
while True :
laLettre = input("Tapez la lettre à tester : ")
# Rajout du test d'appartenance de la lettre à tester avant d'agir
if ( laLettre in motSecret ) :
# Création de motTemporaire pour mettre motTrouve a jour
motTemporaire = ""
for index in range(len(motSecret)) : # Pour chaque caractère-element contenu dans trucSecret
if ( motSecret[index] == laLettre ) :
motTemporaire = motTemporaire + motSecret[ index ]
else :
motTemporaire = motTemporaire + motTrouve[ index ]
motTrouve = motTemporaire
print(motTrouve)
14° Testez avec le mot à découvrir Bonjour et en demandant de vérifier la lettre b minuscule. Ca fonctionne ?
Nous allons donc devoir formater les lettres : le A et le a n'ont pas le même code. Si l'utilisateur demande à savoir s'il y a des A, alors que motSecret contient des a, le programme va répondre que non, il n'y a pas de A...
Pour faire cela, nous pourrions analyser les caractères un par un et les transformer en utilisant un test IF pour chaque lettre... Heureusemet, il y a mieux : il y a les méthodes des strings.
Les méthodes des strings déja rencontrées
split : pour renvoyer une liste composée de la décomposition d'un string. Par défaut, le caractère séparateur est l'espace.
Exemple :
phrase = "A AB A.B.C."
mots = phrase.split()
print(mots)
[ 'A', 'AB', 'A.B.C' ]
phrase = "A AB A.B.C."
mots = phrase.split('.')
print(mots)
[ 'A AB A', 'B', 'C' ]
isnumeric : pour vérifier qu'un string n'est composé que de chiffres de 0 à 9.
>>> '12.3'.isnumeric()
False
>>> '12,3'.isnumeric()
False
>>> '12'.isnumeric()
True
>>> '12E3'.isnumeric()
False
replace : pour obtenir un nouveau string où certains caractères particuliers sont transformés en autre chose. Attention, on ne TRANSFORME pas le string : on renvoie une version où les caractères sont transformées.
>>> monTexte = "Bonjour"
>>> monTexte.replace('o','i')
'Binjiur'
>>> monTexte
'Bonjour'
>>> monTexte = monTexte.replace('jour','soir')
>>> monTexte
'Bonsoir'
Voyons maintenant quelques autres méthodes pratiques pour comparer les chaînes de caractères ou les caractères entre eux :
Trois nouvelles méthodes des strings bien pratiques
upper : renvoie une version du string où les caractères sont tous en majuscules. Le string de base n'est pas modifié. On renvoie juste un autre string où les changements sont faits.
Exemple :
>>> 'azerty &é"àç'.upper()
'AZERTY &É"ÀÇ'
lower : renvoie une version du string où les caractères sont tous en minuscules. Le string de base n'est pas modifié. On renvoie juste un autre string où les changements sont faits.
Exemple :
>>> ''AZERTY &É"ÀÇ'.lower()
'azerty &é"àç'
isalpha : renvoie True si le string ne contient QUE des caractéres alphabétiques (des lettres). Cela permet par exemple de vérifier que le mot à trouver est bien un mot. Sinon, le jeu risque d'être un peu long ...
Exemple :
>>> ''AZERTY'.isalpha()
True
>>> ''AZERTY2'.isalpha()
False
>>> ''AZéRTï'.isalpha()
True
>>> ''AZ*RTY'.isalpha()
False
15° Améliorer le test du pendu en comparant non pas le vrai contenu de laLettre et motSecret[ index ] mais en comparant deux versions intégralement en majuscules ou en minuscules. Ainsi demandant A devrait revéler les a et les A. Et l'inverse devrait vrai aussi.
16° Finaliser enfin en gérant le while et en vérifiant la validité initiale du mot proposé : il faudrait faire un split-espace et un split-tiret. Puis vérifier que chaque élément de la liste est bien composé uniquement de lettres.
...CORRECTION ...
#!/usr/bin/env python
# -*-coding:Utf-8 -*
testDepart = False
while testDepart == False :
motSecret = input("Tapez votre string secret : ") # On demande motSecret
for element in motSecret.split() : # Pour chaque caractère-element contenu dans trucSecret
testDepart = element.replace("-","").isalpha()
# Création du string de réponse trouvée
motTrouve = ""
for element in motSecret : # Pour chaque caractère-element contenu dans trucSecret
if (element !=' ' and element !='-') :
motTrouve = motTrouve + '*' # Rajoute *
else :
motTrouve = motTrouve + element # Rajoute element (espace ou tiret)
# Boucle du jeu
while motTrouve != motSecret :
laLettre = input("Tapez la lettre à tester : ")
if ( laLettre.upper() in motSecret.upper() ) :
# Création de motTemporaire pour mettre motTrouve a jour
motTemporaire = ""
for index in range(len(motSecret)) : # Pour chaque caractère-element contenu dans trucSecret
if ( motSecret[index].upper() == laLettre.upper() ) :
motTemporaire = motTemporaire + motSecret[ index ]
else :
motTemporaire = motTemporaire + motTrouve[ index ]
motTrouve = motTemporaire
print(motTrouve)
print("Gagné !")
input("pause")
Il est temps d'arrêter. Ce n'est pas encore parfait. On pourrait remplacer les é,è,ê par un simple e. Idem pour les à ... On pourrait compter les étapes ou même proposer de découvrir le mot avant la fin. Mais vous avez vu l'essentiel.
Sachez qu'il existe encore beaucoup de méthodes applicables aux strings. Vous pourrez les découvrir en faisant une recherche sur Internet ou alors simplement en allant voir la fiche de ce site :
5 - Mise en pratique : des exercices (pas faciles !)
Pour stabiliser toutes ces nouvelles connaissances (dont le isalpha()), voilà trois exercices.
17° Mini-projet 1 : je voudrais distinguer les gens par le nombre moyen de caractères par phrase écrite. Je pense montrer que ce nombre moyen est corrélé avec la formation et la durée de la formation. Je voudrais donc pouvoir compter le nombre de lettres de la première phrase d’un texte. Il faudra donc :
- Lire le texte phrase par phrase. On utilisera la méthode split avec le point comme élément séparateur : cela permettra de récupérer les phrases dans une liste. Chaque élement de la liste est donc une phrase.
- Lire uniquement l'élément 0 de cette liste : on obtiendra la première phrase.
- Lire les caractères de la première phrase, un à un à l’aide d’une boucle for.
- Créer un compteur qui va s’incrémenter de 1 si le caractère est bien une lettre (voir la méthode isalpha présentée ci-dessus).
- Afficher le nombre de lettres (alphabétiques donc) rencontrées sur la première phrase.
Tester le programme avec :
monTexte = "Voilà la première phrase, celle dans laquelle il faut compter les caractères, enfin sauf les virgules, les espaces et les points. On ne devrait pas compter non plus les ; mais comme c'est une seconde phrase, cela n'a pas d'importance."
Vous devriez trouver 105 caractères.
Mini-projet 2 : nous allons maintenant manipuler les caractères via leurs codes ASCII.
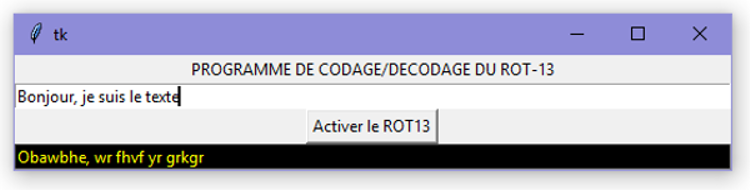
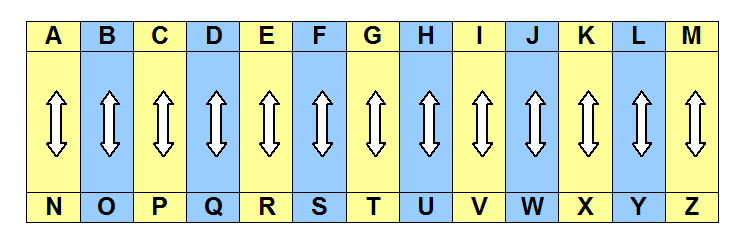
Le cryptage ROT-13 : c’est un codage primitif, datant de l’époque où les calculateurs automatiques n’existaient pas. On décale toutes les lettres de 13 lettres. Comme l’alphabet en comporte 26, l’avantage est que le codage et le décodage nécessite le même algorithme.
A devient N, N devient A.
B devient O, O devient B.
…
M devient Z, Z devient M.
Ceci en majuscule, comme en minuscule.
Voilà un bout de code qui va vous permettre :
- de créer un widget-label rattaché au StringVar texteEntree. On pourra lire le contenu à traiter en utilisant
texteEntree.get(). - de créer un widget-bouton permet d’activer la fonction rot13.
- de créer un autre widget-label rattaché au StringVar texteSortie. On pourra modifier son contenu en utilisant
texteSortie.set("NOUVEAU TEXTE").
#!/usr/bin/env python
# -*-coding:Utf-8 -*
from tkinter import *#pour la gestion des fenêtres
# - - - - - - - - - - - - - - -
# Déclaration des fonctions
# - - - - - - - - - - - - - - -
def rot13():
# A vous de completer et de modifier cette fonction
stringDeBase = texteEntree.get()# récupère le texte à encoder ou décoder
stringModifie = stringDeBase # A modifier
texteSortie.set(stringModifie)
# - - - - - - - - - - - - - - -
# CREATIONS DE LA FENETRE ET DES WIDGETS QUI LA COMPOSE
# - - - - - - - - - - - - - - -
# CREATION DE L'OBJET FENETRE
fen_princ = Tk()
# CREATION DE LA ZONE LABEL-TITRE
Label(fen_princ, text = "PROGRAMME DE CODAGE/DECODAGE DU ROT-13").pack()
# CREATION DE LA ZONE DE LECTURE
texteEntree = StringVar()# contient le texte de base
texteEntree.set("INSERER ICI VOTRE TEXTE")# On définit le texte affiché au début
= Entry(fen_princ, textvariable = texteEntree, width = 200)
.pack()# On rajoute le widget à la fenêtre
# Création d'un Button lancant le ROT13
Button(fen_princ, text = "Activer le ROT13", command = rot13).pack()
# CREATION DE LA ZONE DE RESTITUTION après codage
texteSortie = StringVar()# contient le texte encodé
texteSortie.set("--- C'est ici qu'apparaitra le texte codé ou décodé ---")
= Entry(fen_princ, textvariable = texteSortie, bg = "black", fg = "yellow", width = 200)
.pack()#On rajoute le widget à la fenêtre
# Lancement de la boucle de surveillance sur la fenêtre fen_princ
.mainloop()
Le caractère A correspond au code 65 et Z correspond au code 90 lorsqu'on utilise respectivement ord("A") et ord("Z").
A l'inverse, chr(65) renvoie A et chr(90) renvoie Z.
ATTENTION : vous n'aurez qu'à modifier le contenu de la fonction rot13. Inutile de chercher à modifier le code ailleurs pour répondre aux questions.
18° Modifier et compléter la fonction rot13 donnée de façon à :
- lire (et enregistrer) avec ord le code ASCII de chaque caractère du texte stocké dans stringDeBase
- rajouter 13 à ce code
- trouver avec chr le nouveau caractère à afficher.
- recréer le nouveau texte stringModifie à l’aide des nouveaux caractères.
Votre code devrait vous permettre de gérer parfaitement l'encodage de A à M. Mais pas encore de N à Z !
Testez votre interface : si vous rentrez ABC , elle devrait vous répondre NOP . Idem en minuscule.
...CORRECTION ...
def rot13():
stringDeBase = texteEntree.get()# récupère le texte à encoder ou décoder
stringModifie = ""
for caractere in stringDeBase :
code = ord(caractere) + 13
stringModifie = stringModifie + chr(code)
texteSortie.set(stringModifie)
Le problème du caractère N ? Il renvoie [ et pas A . Pourquoi ?
C'est simple : ord('N') renvoie le code 78. 78+13 vaut 91. Or chr(91) est bien le caractère après le Z : cela renvoie [ .
| Type | Décimal | Symbole | Binaire |
|---|---|---|---|
| Printable | 65 | A | 100 0001 |
| Printable | 66 | B | 100 0010 |
| ... | .. | . | ... .... |
| Printable | 77 | M | 100 1101 |
| Printable | 78 | N | 100 1110 |
| Printable | 79 | O | 100 1111 |
| ... | .. | . | ... .... |
| Printable | 90 | Z | 101 1010 |
| Printable | 91 | [ | 101 1011 |
| Printable | 92 | \ | 101 1100 |
19° Gérer le code pour qu'on ne puisse pas :
- dépasser 90(Z) : on doit continuer sur 65(A) et plus
- dépasser 122(z) : on doit continuer sur 97(a) et plus
Testez votre interface avec ABCNOP , elle devrait vous répondre NOPABC . Idem en majuscule.
...CORRECTION ...
def rot13():
stringDeBase = texteEntree.get()# récupère le texte à encoder ou décoder
stringModifie = ""
for caractere in stringDeBase :
code = ord(caractere) + 13
if (code > 90 or code > 122) :
code = code-26
stringModifie = stringModifie + chr(code)
texteSortie.set(stringModifie)
Dernière amélioration pour aujourd'hui : ABC NOP devrait vous donner NOP-ABC . Et oui : 32 est le code de l'espace et 32+13 = 45 est le code du tiret.
20° Rajouter un filtre sur la lecture et la modification du code du caractère : on ne doit rien faire si le code de base n'est pas celui de A à Z ou de a à z.
Testez votre code : ABC NOP devrait maintenant vous donner NOP ABC . Ouf.
Si vous avez besoin d'aide, n'hésitez à me contacter. Il suffit de quelques tests bien placés.
Mini-projet 3 : S'il vous reste un peu de temps, vous pourriez faire un jeu du pendu en mode Tkinter. A vous de faire.
Voilà un exemple d'interface graphique. Vous pouvez télécharger l'exe Windows en cliquant sur l'image.

6 - FAQ
Question : Il existe encore d'autres méthodes applicables sur les strings ?
Oh oui. Beaucoup. Vous pourrez les trouver sur la fiche ou sur Internet.
A titre d'exemple intéressant pour vous : monString.format(*args, **kwargs)
L'utilisation basique est celle d'un remplissage progressif des "trous" provoqués par les accolades {} :
>>> a = "Bonjour {}, aujourd'hui nous sommes {}."
>>> print( a.format('jeune Skywalker','jeudi') )
Bonjour jeune Skywalker, aujourd'hui nous sommes jeudi.
Mais on peut faire mieux encore : on peut donner un ordre d'affichage : {1} veut dire d'aller chercher l'élément d'index 1 dans la liste des éléments donnés. Attention, l'élément d'index 0 est le premier, comme toujours.
>>> a = "Bonjour {1}, aujourd'hui nous sommes {0}."
>>> print( a.format ("vendredi, pouf, ça passe vite","Yoda"))
Bonjour Yoda, aujourd'hui nous sommes vendredi, pouf, ça passe vite.
Ou encore, et ça devient intéressant :
>>> a = "Aujourd'hui, nous sommes {3}".
>>> a.format('lundi', 'mardi', 'mercredi', 'jeudi', 'vendredi', 'samedi', 'dimanche')
'Aujourd'hui, nous sommes jeudi.'
Et ce n'est que le tout sommet de l'iceberg. Il y a beaucoup trop à dire. Cela mérite une fiche à part.
A titre d'exemple :
>>> jours = ('lundi', 'mardi', 'mercredi', 'jeudi', 'vendredi', 'samedi', 'dimanche')
>>> a = "Bonjour, nous sommes {b[3]}."
>>> a.format(b=jours)
'Bonjour, nous sommes jeudi.'
Question : on peut lire les caractéres d'un string sans passer nécessairement par un for ? Oui, on peut utiliser range :
Pour lire le contenu des cases de 0 à 9 (c'est à dire tant que case < 10), on peut écrire :
x = "Bonjour les gens"
for i in range(0,10) : # On peut écrire plus simplement in range(10)
print(x[i], end="")
print()
Bonjour le
On obtient les cases de 0 à 9 (car c'est i<10) : Bonjour le, c'est à dire la portion en jaune de Bonjour les gens
On peut obtenir le même effet avec les instructions suivantes :
x = "Bonjour les gens"
print(x[0:10]) # On peut écrire plus simplement x[:10]
Bonjour le
Pour lire le contenu des cases de 2 à 9 (c'est à dire tant que case < 10), on peut écrire :
x = "Bonjour le monde"
for i in range(2,10) :
print(x[i], end="")
print()
njour le
On obtient les cases de 2 à 9 (car c'est i<10) : njour le, c'est à dire la portion en jaune de Bonjour les gens
On peut obtenir le même effet avec les instructions suivantes :
x = "Bonjour le monde"
print(x[2:10])
njour le
Pour lire le contenu des cases de 2 à 9 de deux en deux, on peut écrire :
x = "Bonjour le monde"
for i in range(2,10,2) :
print(x[i], end="")
print()
norl
On obtient les cases de 2 à 9 (car c'est i<10) : norl, c'est à dire la portion en jaune de Bonjour les gens
On peut obtenir le même effet avec les instructions suivantes :
x = "Bonjour le monde"
print(x[2:10:2])
norl
On peut omettre de noter certains paramètres. Il suffit de ne pas le mettre mais de placer le : suivant.
Si on ne place pas le caractère initial, l'interpréteur remplacera par 0.
Si on ne place pas le caractère final, l'interpréteur ira jusqu'au bout de la chaïne.
Si on ne place pas la valeur de l'itération, l'interpréteur ira augmentera de 1 en 1.
Ainsi les cas suivants sont équivalents :
>>> x = "Bonjour"
>>> print(x[0:5:1])
Bonjo
>>> print(x[0:5])
Bonjo
>>> print(x[:5])
Bonjo
Question : Comment lire un string à l'envers ?
Et un dernier truc pour la route : comment inverser une chaîne de caractère ? Il suffit de lui dire de compter non pas en 1 mais en -1 !.
Ici, je ne précise ni le début de la chaîne, ni la fin. J'ai donc noter :: pour indiquer que je donne uniquement la valeur de l'itération.
>>> x = "Bonjour"
>>> print(x[::-1])
ruojnoB
Voilà. Comme pour les images, ceux qui voudront travailler sur un projet lié à la gestion de texte auront l’occasion d’aller beaucoup plus loin.
L'activité sur l'encodage nous permettra d'ailleurs d'explorer certaines fonctions qui encodent et décodent automatiquement, tant qu'on leur parle bien.