3 - Gérer une base de données en utilisant le SQL
SQL veut dire Structured Query Language : Langage structuré de requêtes.
Il s'agit d'un des langages communs les plus courants pour gérer ces bases de données. Il est assez standardisé et sauf exeption sur un détail ou deux, les requêtes sont compréhensibles par la plupart des bases qui utilisent ce langage. Ainsi une base MySQl ou ORACLE auront des codes SQL très proches (mais pas identiques). C'est un peu comme les commandes CSS avec les différents navigateurs Web.
Nous allons voir ici commment créer des tables, les remplir et afficher leur contenu.
Pour obtenir plus d'informations qu'ici sur le SQL, une adresse que vous devez déjà connaitre :
Ce site est toujours très complet. Ici, il expose en plus clairement les petites différences de synthaxe SQL entre les différentes bases de données.
1 - Création et destruction des tables
01° Ouvrir XAMP et activer le serveur Apache et la base de données MySQL.
02° Cliquer sur Admin au niveau de MySQL pour ouvrir l'interface php phpMyAdmin.
03° Commencer par créer une base de données en cliquant sur SQL et en tapant le code suivant :
CREATE DATABASE testDB;
Si vous aviez déjà sélectionnné une base de données, vous pouvez cliquer sur Nouvelle base de données.
On remarquera que nous avons pris le partie de mettre les instructions en majuscules, mais ce n'est pas obligatoire. Néanmoins, puisque nous utiliserons SQL à travers d'autres langages, cela permet de voir ce qui découle de SQL et ce qui découle du langage de programmation.
Retenons par principe que ceci fonctionne également :
create database testDB;
On remarquera également que les instructions sont finalisés par un point-virgule.
04° Sélectionner votre BDD puis SQL pour insérer un premier code pour créer une table et y mettre des champs.
CREATE TABLE jeux2 (
id SMALLINT,
jeu VARCHAR(20),
description TEXT,
sortie YEAR,
editeur VARCHAR(20),
idSupport SMALLINT
);
Pour être plus précis et éviter de vérifier si nous sommes sur la bonne base de données, il est possible de préciser qu'on travaille avec la table jeux3 de la base de données testDB. Comme pour les objets, on sépare les deux d'un point.
CREATE TABLE testDB.jeux2 (
...
);
Comme vous pouvez le constater, on donne l'instruction CREATE TABLE, le nom de la table, on ouvre une parenthèse puis on donne la définition des différents champs, séparées par une virgule. A la fin du dernier champ, on referme la parenthèse et on finalise par un point-virgule.
Et si on veut les détruire ?
C'est simple également : on utilise DROP TABLE.
DROP TABLE jeux2 ;
2 - Création des clés primaires
Néanmoins, pour l'instant, nous n'avons pas défini de clé primaire pour notre table. Comment faire ? Voici le code type :
05° Sélectionnner votre BDD et utiliser le code suivant pour créer une seconde table, plus élaborée.
CREATE TABLE testDB.jeux3 (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
jeu VARCHAR(20),
description TEXT,
sortie YEAR,
editeur VARCHAR(20),
idSupport SMALLINT UNSIGNED NOT NULL,
PRIMARY KEY (id)
);
La création de la clé primaire passe donc par la commande PRIMARY KEY .
Il reste à créer une autre table supports pour les supports
- Un identifiant nommée idSupport.
- Le nom sous forme d'un VARCHAR de 20 caractères.
- Le RAM sous forme d'un VARCHAR de 20 caractères.
- La date_sortie qui correspond à un YEAR encodant l'année de sortie du support.
06° Créer cette table.
On cherche, la solution est un peu plus bas.
Voici la correction si vous n'avez pas réussi à le faire seul :
CREATE TABLE supports (
idSupport SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
nom VARCHAR(20),
RAM VARCHAR(20),
date_sortie YEAR,
PRIMARY KEY (idSupport)
);
La notation vue ici vaut pour les bases "MySQL".
Sur les bases "SQL Server", "Oracle" ou "MS Access", on doit utiliser simplement :
idSupport SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
);
3 - Rajouts d'entrées dans les tables
Nous allons maintenant voir comment rentrer les données dans une table à l'aide des commandes SQL.
En voici un exemple valable si vous voulez renseigner tous les champs de votre entrée :
INSERT INTO jeux3
VALUES (NULL,'Flight Simulator','Simulateur d\'avion avec des pixels gros comme des pixels',1980,'SubLOGIC',1);
Point-virgule : on remarque que le point-virgule n'est placée qu'une fois l'instruction complète terminée et non pas dès la fin du INSERT INTO.
Avec cette méthode, on précise donc d'abord la table sur laquelle agir avec INSERT INTO.
Ensuite, on donne les valeurs avec VALUES en plaçant entre parenthèses les valeurs à insérer.
Pour rappel, voici la structure de notre table :
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
jeu VARCHAR(20),
description TEXT,
sortie YEAR,
editeur VARCHAR(20),
idSupport SMALLINT UNSIGNED NOT NULL,
PRIMARY KEY (id)
07° Pourquoi ne doit-on pas préciser le numéro de id mais noter NULL ?
...CORRECTION...
Envoyer NULL permet de signaler qu'il s'agit bien de la valeur à placer dans id, à savoir "ne rien placer".
Puisqu'on remplit l'entrée sans préciser le nom des colonnes à remplir, nous sommes obligé de toutes les données, même si on ne met rien dedans...
Sinon, la base de données est perdue lorsqu'elle reoit l'instruction : il lui manquerait une donnée.
08° Les guillemets SIMPLES sont impératifs pour délimiter les chaînes de caractères en SQL. Pas de guillemets doubles. Comment parvient-on à placer des guillemets simples dans les chaînes à enregister ?
...CORRECTION...
On utilise \' avec \ comme caractère d'échappement.
09° Utiliser l'exemple. Puis, sur le même principe, rajouter ensuite une seconde entrée.
Si on ne veut renseigner que certains champs, on doit utiliser une synthaxe légérement différente :
INSERT INTO jeux3 (jeu,sortie,idSupport)
VALUES ('Pitfall !', 1982,2);
Comme vous le voyez, on donne lors du INSERT INTO les noms des champs qui vont être fournis en dessous. Nous n'avons alors plus besoin de placer NULL pour les champs que nous ne voulons plus remplir. Ou alors, c'est qu'on veut vraiment placer certaines entrées à NULL sur certains champs.
Ordre des champs : L'autre intérêt vient du fait que vous n'avez plus besoin de placer les champs dans l'ordre de la table : vous pouvez les donner dans l'autre que vous voulez.
10° Utiliser l'exemple et rajouter encore une quatrième entrée.
Enregistrer les entrées une à une est un peu fatiguant non ? Il existe heureusement un moyen d'aller plus vite :
INSERT INTO jeux3 (jeu,description,sortie,editeur,idSupport)
VALUES
('Pitfall !', 'Vous êtes Pitfall Harry, un courageux aventurier façon Indiana Jones, perdu au beau milieu d\'une jungle très hostile. Vous avez 20 minutes pour trouver un maximum de trésors tout en bravant les multiples dangers de la jungle : éviter les crocodiles, les scorpions, les serpents, le feu, les sables mouvants et les troncs d\'arbres qui roulent en votre direction. Vous n\'avez que 3 vies, et pas une de plus.', 1982,'Activision',2),
('Space Invaders', 'Vous devez protéger la Terre d\'une invasion d\'aliens. Heureusement, ils ont un peu de mal à bouger en 3D !', 1980,'Taito',2),
('DECATHLON', '10 épreuves d\'athlétisme où l\'essentiel du gameplay consiste à secouer le joystick le plus vite possible !', 1983,'Activision',1);
On notera que les différent blocs de valeurs sont données entre parenthèses et séparés par des virgules. Le bloc final est suivi d'un point-virgule puisqu'il s'agit de la fin de l'instruction.
11° Lancer l'exemple. Vous devriez obtenir quelque chose comme :
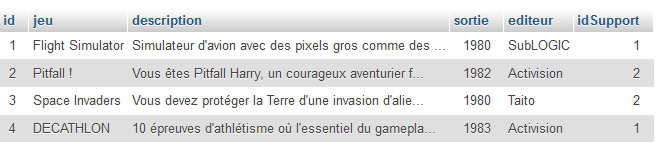
12° Il vous reste à recréer ceci en utilisant les lignes de code :

Comment parvenir à enregistrer la date de sortie alors que nous avons crée uniquement un champ YEAR ? En utilisant le chapitre suivant !
Vous avez certainement utilisé un code du type :
INSERT INTO testdb.supports (nom,RAM,date_sortie)
VALUES
('Apple II','4 Ko','1977-06-10'),
('Atari 2600','4 Ko', '1977-10-14'),
('C64','64 Ko','1982-08-01');
DATE : on notera que DATE utilise la notation anglo-saxonne : AAAA-MM-JJ.
4 - Modifications des champs ou des entrées
Commençons par voir comment modifier le type d'un champ existant :
ALTER TABLE testdb.supports
MODIFY COLUMN date_sortie DATE;
13° Utiliser le code. Vous devriez constater que le type est bien changé. Par contre, en allant voir le contenu, vous devriez voir que le contenu précédent a disparu... Nous n'avons pas été assez prudent en manipulant nos données. Attention : cela arrive très (trop) souvent.
Bref, il faudrait le rentrer à nouveau.
Pour supprimer un champ dans une table :
ALTER TABLE testdb.supports
DROP COLUMN date_sortie;
Pour rajouter un champ :
ALTER TABLE testdb.supports
ADD COLUMN date_sortie DATE;
On remarquera qu'il faut fournir le type du nouveau champ.
Nous allons maintenant rajouter à la main les dates que nous avons fait disparaitre malheureusement :
UPDATE testdb.supports
SET date_sortie='1977-06-10'
WHERE nom='Apple II';
En fançais, cela donne : Dans la table testdb, change (UPDATE) les champs date_sortie pour les placer à 1977-06-10 de la table testdb pour toutes les entrées dont le champ nom est Apple II.
Et c'est là que c'est puissant : ici, seule une entrée est changée. Mais il peut en changer beaucoup. Et rapidement.
D'ailleurs, si vous placez WHERE 1 ou si vous oubliez le WHERE, toutes les entrées de la table seront affectées.
14° Utiliser ceci pour rajouter les deux dates qui manquent.
On peut supprimer des colonnes avec DROP mais on peut aussi supprimer une ou des entrées sous condition :
DELETE FROM testdb.supports
WHERE nom='Apple II';
15° Ne lancez pas le code. Mais que fait-il sinon ?
5 - Clés étrangères
Il reste encore à voir comment lier les tables entre elles à l'aide des clés étrangères.
Souvenez-vous du concept : on utilise un champ dans une table qui va correspondre à la clé primaire d'une autre table.
Dans notre exemple, idSupport de la table jeux3 contient un entier. Cet entier correspond à la clé primaire de la table Supports.
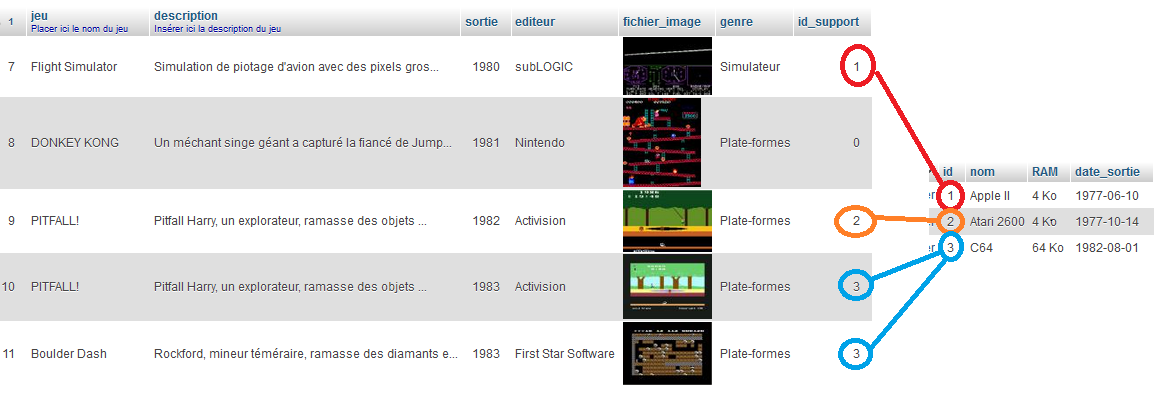
Rappel : les deux champs doivent impérativement être exactement du même type (si ce n'est que le premier ne doit pas être une clé primaire). Par contre, ils n'ont pas à porter le même nom même si c'est bien pratique pour faire le lien facilement entre les deux tables.
Voici ce que nous aurions dû faire dès la création de la table jeux3 après avoir créer la table supports :
CREATE TABLE testDB.jeux3 (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
jeu VARCHAR(20),
description TEXT,
sortie YEAR,
editeur VARCHAR(20),
idSupport SMALLINT UNSIGNED NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (idSupport) REFERENCES supports(idSupport)
);
Comme vous le voyez, une seule ligne bien placé en fin de création.
Nous, c'est un peu différent : la table est déjà créée.
ALTER TABLE testDB.jeux3
ADD FOREIGN KEY (idSupport) REFERENCES testDB.supports(idSupport)
16° Créer le lien entre les deux tables.
Et maintenant, on retrouve toute la puissance du JOIN de la partie précédente.
6 - Select
C'est la dernière chose très pratique. Comment sélectionner des éléments ?
C'est l'une des requetes les plus puissantes de SQL Nous allons pouvoir filtrer, trier et faire le lien entre différentes tables.
17° Importer (à l'aide du menu vertical) l'exemple de base de données suivante :
LA TABLE testdb2 à télécharger.
Attention, j'ai mis un indice 2 pour bien la distinguer de votre propre base. Si votre base est conséquente, vous pouvez la garder.
Voici le contenu des deux tables jeux3 et supports :
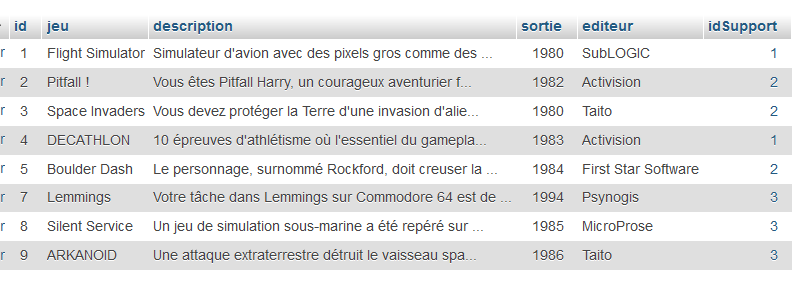
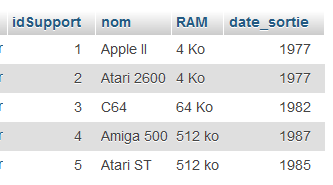
Voici la première chose à savoir faire : sélectionner ce qu'on veut sur une table.
Pour sélectionner tous les éléments, on utilise le symbole * :
SELECT * FROM jeux3 ;
ou
SELECT *
FROM jeux3 ;
Cette instruction va simplement vous sortir la table jeux3.
Comme on peut le voir, le résultat est fourni en le triant sur l'ID PRIMAIRE de l'entrée.
Pour trier les données en fonction d'un champ, il faut utiliser l'instruction ORDER BY. Les lignes ci-dessous (que vous pouvez placer sur une seule ligne si vous le voulez), permettent de sortir les entrées et de les classes par date de sortie :
SELECT *
FROM testdb2.jeux3
ORDER BY sortie;
18° Lancer une commande permettant de sortir la liste des jeux par ordre alphabétique en triant selon le résultat en fonction du nom du jeu :

On peut également filtrer les entrées en fonction d'un paramètre : on utilise alors la commande WHERE qui va permettre de rajouter une condition de choix :
SELECT *
FROM testdb2.jeux3
WHERE sortie > 1985
ORDER BY jeu;

On peut même faire mieux et utiliser des conditions multiples en utilisant les mots-clés ADD et OR (pour ET et OU respectivement pour ceux qui ne suivent vraiment pas).
SELECT *
FROM testdb2.jeux3
WHERE sortie > 1985 AND jeu < 'C'
ORDER BY jeu;
Le test d'égalité ne se fait pas avec un signe égal double. SQL n'est pas un langage de programmation, le = n'est donc pas lié à l'affectation d'une variable. Il suffit donc de faire un test d'égalité entre un champ et une valeur. Par exemple editeur = 'Taito'
19° Tentez de sélectionner les jeux dont la première lettre est inférieure strictement à M et dont le IdSupport vaut 2.

c'est bien beau, mais on ne veut pas forçément tout récuperer : la description ou la date de sortie peuvent très bien ne pas me servir du tout pour la tache que je veux réaliser. On peut alors décider d'être plus précis dans le SELECT et prendre uniquement les champs dont on a besoin. On suffit de ne plus utiliser l'étoile *.
Vous devriez avoir utiliser un code du type ci-dessous pour répondre à la question précédente :
SELECT *
FROM testdb2.jeux3
WHERE jeu < 'M' AND idSupport = 2
ORDER BY jeu;
Pour ne sélectionner que le nom et le support du jeu, je peux lancer ceci :
SELECT jeu, idsupport
FROM testdb2.jeux3
WHERE jeu < 'M' AND idSupport = 2
ORDER BY jeu;
On obtient alors :
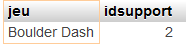
20° Lancer une requête pour obtenir le nom, le numéro d'idSupport et la date de sortie des jeux sortis après 1980 OU dont l'idSupport strictement est supérieur à 3.
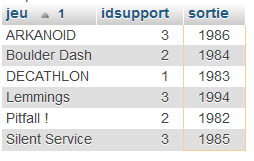
7 - Opérations spéciales
Mais on peut faire mieux encore. On peut compter, additionner ou faire une moyenne.
Si je veux obtenir le nombre de jeux sortis après 1985 :
SELECT COUNT(*)
FROM testdb2.jeux3
WHERE sortie > 1985;
Si je veux obtenir l'année moyenne de sortie de jeux sur le support 3, on peut utiliser la fonction moyenne (average en anglais) qui donne AVG en SQL :
SELECT AVG(sortie)
FROM testdb2.jeux3
WHERE idSupport = 3;
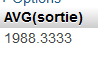
Et même si cela n'a aucun sens, on pourrait sortir la somme des années de sortie :
SELECT SUM(sortie)
FROM testdb2.jeux3
WHERE idSupport = 3;
8 - Jonction
Tout cela est bien joli mais on reste cloisonné à une unique table. Et faire référence à un ordinateur en utilisant idSupport ce n'est pas très compréhensible pour un humain.
Nous avions déjà vu la commande INNER JOIN qui permet de faire le lien entre une table et une autre en utilisant les clés étrangères.
Mais il y a beaucoup de façons de faire la liaison entre deux tables :
Imaginons que nous voulions afficher les jeux et leurs supports : on veut sélectionner tous les noms de jeux dans la table jeux3 et afficher la valeur nom stockée dans la table supports qui correspond à l'idSupport du jeu.
SELECT jeux3.jeu, supports.nom
FROM jeux3,supports
WHERE jeux3.idSupport = supports.idSupport;
Et cela donne :
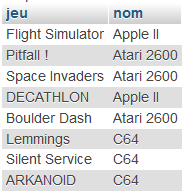
21° Rajouter une condition avec un ADD pour ne voir que les jeux sortis après 1985 :
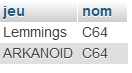
L'intéret de cette méthode est qu'on peut les n'importe quel lien. Aucun besoin de clés étrangères. Il suffit d'avoir des valeurs qui puissent être les mêmes et qu'elles soient uniques dans l'une des tables.
Autre façon de faire : on ne crée par la liaison avec une condition dans le WHERE mais en utilisant l'instruction JOIN :
Cette méthode va permettre à une entrée de la table jeux3 d'aller lire un champ de la table support en utilisant idSupport comme liaison.
SELECT jeux3.jeu, supports.nom
FROM jeux3
JOIN supports USING(idSupport);
Comme il n'y a pas d'ambiguité sur les noms de champs, on peut même utiliser :
SELECT jeu, nom
FROM jeux3
JOIN supports USING(idSupport);
Il s'agit donc de faire ses recherches sur une table mais de rajouter les champs d'une autre table en utilisant le champ donné derrière USING pour faire le lien. Ce champ doit donc être partagé par les deux tables et porter le même nom.
Si les deux champs ne portent pas le même nom, il faut utiliser ON plutôt que USING :
SELECT jeu, nom
FROM jeux3
JOIN supports ON jeux3.idSupport = supports.idSupport;
Ici, les deux champs portent bien le même nom mais vous comprenez le principe.
Il reste la question du INNER. En réalité, il existe plusieurs types de JOIN. Par défaut, il s'agit de INNER JOIN si vous notez juste JOIN.
SELECT jeu, nom
FROM jeux3
INNER JOIN supports ON jeux3.idSupport = supports.idSupport;
Cela donnera également :
Le INNER JOIN renvoie donc les résultats pour lesquels le champ idSupport de la première table correspond à celle de la seconde table.
Voilà pour aujourd'hui. Nous verrons pas les autres types de jonction possibles dans cette activité. Sachez simplement comment elles fonctionnent (si cela peut vous servir dans l'une de vos requêtes) :
LEFT JOIN renvoie toutes les entrées qui correspondent bien entre les deux champs ET rajoute les entrées de la première table (jeux3 ici) même s'il ne trouve pas de correspondance dans la seconde.
RIGHT JOIN fait l'inverse : vous aurez donc toutes les entrées qui correspondent ET les entrées de la deuxième qu'on aurait mis de côté sinon.
Nous verrons peut-être cela dans une autre activité. Si vraiment vous en avez besoin, voici un excellent article qui en parle :