Python-Physique 09 : Listes et Tableurs
L'activité suivante présente la faculté de Python et matplotlib à tracer des vecteurs. Vecteurs qui apparaissent notamment dans la partie mécanique. Partie mécanique où nous travaillons sur une vidéo pour récupérer les positions des objets étudiés. Et justement : nous n'allons pas devoir retaper les mesures effectuées avec le logiciel de traitement vidéo. Nous allons voir comment récupérer directement ces données !
Cette activité décrit donc comment enregistrer nos données, à partir du clavier ou d'un fichier stocké sur votre ordinateur.
1 - Rappel : création directe et lecture des listes
Deux façons de créer des listes de données :
- Une façon directe : on donne les valeurs :
listeI = [ 0, 10.2, 19.8, 38.9 ]
- Une façon indirecte : on calcule les valeurs :
listeI = [ x/1000 for x in range(0,301,20) ]
Qu'est qu'une liste ? C'est une suite ordonnée et modifiable (mutable) d'objets ou variables quelconques.
Les éléments d'une liste sont séparés par des virgules et la définition de la liste commence avec [ et s'arrête avec ].
maListe = [1,'a',45.2,"bonjour",'b'] crée une liste de 5 éléments contenant l'integer 1, le char a, le float 45.2, le string bonjour et le char b.
Si on veut afficher une liste dans la console Python, print(maListe) fonctionne.
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> print(maListe)
[1,'a',45.2,'bonjour','b']
Si on veut connaitre le nombre d'éléments dans une liste, len(maListe) fonctionne.
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> len(maListe)
5
Si on veut accéder à l'un des éléments d'une liste, on tapera maListe[2], mais attention le premier élément est l'élément 0.
Si on demande print(maListe[2]) avec maListe = [1,'a',45.2,"bonjour",'b'], on obtient :
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> maListe = [2]
45.2
Si on veut accéder à un ensemble d'éléments d'une liste, on tapera ma_liste[1:4], et on aura les éléments 1,2 et 3 (car cela veut dire qu'on commence à l'élément 1 et qu'on s'arrête avant le 4.).
Si on demande print(ma_liste[1:4]) avec ma_liste = [1, 'a', 45.2,"bonjour", 'b'], on obtient :
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> print( ma_liste[1:4] )
['a',45.2,'bonjour']
Pour parcourir une liste, il suffit d'utiliser un for.
for element in maListe :
print(element)
Et on obtient alors
1
a
45.2
bonjour
b
Nous avons également vu qu'on peut utiliser plutôt une boucle for numérique :
for numero in range(len(maListe)) :
print(maListe[numero])
2 - Rajouter ou supprimer des élément dans les listes
Nous allons maintenant voir comment rajouter des éléments à la volée dans des listes préexistantes. C'est pratique pour sauvegarder les mesures réalisées progressivement lors d'un TP par exemple.
Pour rajouter des éléments à une liste, on peut également utiliser un simple + entre deux listes. Attention néanmoins : on crée alors une nouvelle liste qui n'aura pas la même adresse - référence - id que la précédente contrairement à l'utilisation de la méthode append.
Comme la liste est mutable, c'est même plutôt une façon de faire à éviter SAUF si vous voulez clairement créer une nouvelle liste à partir d'une autre liste.
Si on utilise maListe = maListe + ['nouveau'] avec maListe = [1,'a',45.2,"bonjour",'b'], on obtient ainsi :
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> maListe = maListe + ['nouveau']
>>> print(maListe)
['a',45.2,'bonjour','b','nouveau']
Par contre, cette fois, on a recréé une liste qui porte le même nom : ce n'est pas la même liste au niveau de son id.
01° Utiliser l'exemple ci-dessous pour créer une liste et trouver son id (identifiant mémoire). Rajouter quelques éléments en utilisant +. Rechercher ensuite son identifiant mémoire. Conclusion ?
>>> maListe = ['debut', 'milieu', 'fin']
>>> id(maListe)
1820801929032
>>> maListe
['debut', 'milieu', 'fin']
...CORRECTION...
On remarque qu'on a bien rajouté des éléments, que la liste porte le même nom MAIS que ce nom désigne maintenant une zone mémoire différente :
>>> maListe = ['debut', 'milieu', 'fin']
>>> id(maListe)
1820801929032
>>> maListe
['debut', 'milieu', 'fin']
>>> maListe = maListe + ['nouveau début']
>>> maListe = maListe + ['nouvelle fin']
>>> maListe
['debut', 'milieu', 'fin', 'nouveau début', 'nouvelle fin']
>>> id(maListe)
1820802062088
Voyons maintenant comment rajouter des éléments tout en gardant la même adresse mémoire :
Rajouter des éléments dans une liste
L'une des possibilités est d'utiliser la méthode append qui rajoute des éléments en fin de liste.
>>> a = [1,2,3]
>>> a
[1, 2, 3]
>>> a.append('4')
>>> a
[1, 2, 3, '4']
>>> b = [7,8,9]
>>> a.append(b)
>>> a
[1, 2, 3, '4', [7, 8, 9]]
Cette méthode append permet donc de considérer les listes comme des piles de livres : on rajoute les éléments au dessus des derniers éléments.
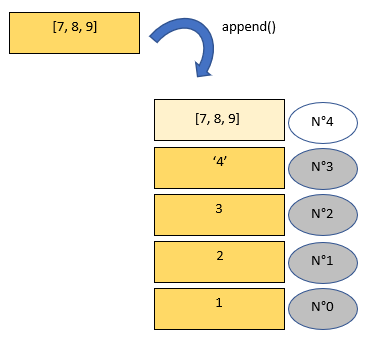
Pas d'affectation ! : on remarque que a est modifiée par la méthode, sans présence du signe =.
Il ne faut pas noter quelque chose comme
a = a.append(b)
Sinon, cela veut dire que vous voulez stocker le résultat de la méthode. Méthode qui ne revoit rien. Vous obtenez alors une variable a ne contenant plus rien !
Attention également : avec append, on rajoute l'élément b, on ne rajoute pas les éléments de b si x est itérable. Ici, on a bien rajouté une liste b dans la liste a et pas les élements de b dans a.
Dans l'exemple, lorsqu'on rajoute la liste [7,8,9], on obtient ainsi :
[ 1, 2, 3, '4', [7, 8, 9] ]
et pas
[ 1, 2, 3, '4', 7, 8, 9 ]
02° Utiliser l'exemple ci-dessous pour créer une liste et trouver son id (identifiant mémoire). Rajouter quelques éléments en utilisant la méthode append. Rechercher ensuite son identifiant mémoire. Conclusion ?
>>> maListe = ['debut', 'milieu', 'fin']
>>> id(maListe)
1820801929032
>>> maListe
['debut', 'milieu', 'fin']
...CORRECTION...
On remarque qu'on a bien rajouté des éléments, que la liste porte le même nom ET que ce nom désigne toujours la zone mémoire initiale :
>>> maListe = ['debut', 'milieu', 'fin']
>>> id(maListe)
1820801929032
>>> maListe
['debut', 'milieu', 'fin']
>>> maListe.append('nouveau début')
>>> maListe.append('nouvelle fin')
>>> maListe
['debut', 'milieu', 'fin', 'nouveau début', 'nouvelle fin']
>>> id(maListe)
1820801929032
Il reste à voir comment insérer des éléments entre deux éléments de la liste ou d'en supprimer.
Si on veut rajouter un élément à une position particulière d'index i dans la liste, on utilise maListe.insert(i,x) où x est l'élément à rajouter et i l'index dans la liste.
>>> maListe = [1,'a',45.2,"bonjour",'b']
>>> maListe.insert(1,'nouveau')
>>> print(maListe)
[1,'nouveau','a',45.2,'bonjour','b']
Souvenez-vous que l'index du premier élément est 0, pas 1.
Si i dépasse l'index maximum, x sera juste ajouté en fin de liste, comme avec un append.
03° Insérer un élément 'nouveau milieu' entre 'nouveau début' et 'nouvelle fin'.
...CORRECTION...
>>> maListe
['debut', 'milieu', 'fin', 'nouveau début', 'nouvelle fin']
>>> maListe.insert(4,'nouveau milieu')
>>> maListe
['debut', 'milieu', 'fin', 'nouveau début', 'nouveau milieu', 'nouvelle fin']
Si on veut supprimer un élément x, on utilise maListe.remove(x) où x est l'élément à supprimer dans la liste.
Si on utilise maListe.remove('nouveau') avec maListe = [1,'nouveau','a',45.2,"bonjour",'b','nouveau'], on obtient :
>>> maListe = [1,'nouveau','a',45.2,"bonjour",'b','nouveau']
>>> maListe.remove('nouveau')
[1,'a',45.2,"bonjour",'b','nouveau']
On remarquera donc qu'elle ne supprime que le premier élément 'nouveau' rencontré. S'il y en a d'autres, il faudra faire d'autres remove.
Attention, si l'élément n'est pas présent dans la liste, la méthode va lever une exception de type valueError. Il faudra donc utiliser un while et un try pour supprimer tous les éléments identiques.
Il existe une autre méthode très pratique : pop supprime le dernier élément ET renvoie le contenu qu'on vient de supprimer : cela permet de l'extraire et le lire.
>>> maListe = [1,'nouveau','a',45.2,"bonjour",'b','nouveau']
>>> lecture = maListe.pop()
>>> maListe
[1,'nouveau','a',45.2,"bonjour",'b']
>>> lecture
'nouveau'
04° Supprimer l'élément 'nouveau début' de votre liste avec la méthode remove puis le dernier élément avec la méthode pop. Afficher l'élément supprimé.
...CORRECTION...
>>> maListe
['debut', 'milieu', 'fin', 'nouveau début', 'nouveau milieu', 'nouvelle fin']
>>> maListe.remove('nouveau début')
>>> maListe
['debut', 'milieu', 'fin', 'nouveau milieu', 'nouvelle fin']
>>> element = maListe.pop()
>>> maListe
['debut', 'milieu', 'fin', 'nouveau milieu']
>>> element
'nouvelle fin'
Si on veut connaitre le nombre de fois qu'un élément x apparait dans une liste, on utilise maListe.count(x) où x est l'élément à surveiller dans la liste.
Si on utilise maListe.count('nouveau') avec maListe = [1,'nouveau','a',45.2,"bonjour",'b','nouveau'], on obtient :
>>> maListe = [1,'nouveau','a',45.2,"bonjour",'b','nouveau']
>>> maListe.count('nouveau')
2
Enfin, deux méthodes qui sont pratiques et un peu l'inverse l'une de l'autre :
Si on utilise maListe.sort(), on ordonne les éléments de la liste maListe.
Exemple 1:
>>> maListe = ['un','deux','trois','quatre']
>>> maListe.sort()
>>> maListe
['deux', 'quatre', 'trois', 'un']
Exemple 2:
>>> maListe = [5,1,3,2]
>>> maListe.sort()
>>> maListe
[1, 2, 3, 5]
Exemple 3: mélange d'int et de str
>>> maListe = ['un','deux','trois','quatre',5,1,3,2]
>>> maListe.sort()
TypeError: '<' not supported between instances of 'int' and 'str'
Donc attention : ce n'est pas une méthode miracle : elle doit pouvoir sélectionner et trier les éléments de type différents entre eux. Si elle ne sait pas faire, ça ne fonctionnera pas.
L'inverse, c'est la fonction shuffle : cette fonction du module random va mélanger les éléments de la liste et les répartir au hasard...
>>> import random as random
>>> maListe = ['un','deux','trois','quatre',5,1,3,2]
>>> random.shuffle(maListe)
>>> maListe
['trois', 'un', 'deux', 2, 1, 'quatre', 3, 5]
Pratique non ?
3 - Recherche du max, du min et de la valeur moyenne
Nous voulons faire des calculs avec les données récoltées.
Pour trouver la valeur maximale dans une liste purement numérique, on utilise max(liste).
Pour trouver la valeur minimale dans une liste purement numérique, on utilise min(liste).
Pour trouver la somme des éléments d'une liste, on utilise sum(liste).
Voilà un exemple des cas précédents et un moyen de calculer une valeur moyenne du coup.
>>> liste = [1,3,5,2,4]
>>> max(liste)
5
>>> min(liste)
1
>>> sum(liste)
15
>>> len(liste)
5
>>> valeur_moyenne = sum(liste)/len(liste)
>>> valeur_moyenne
3.0
Bien entendu, il existe déjà des fonctions permettant de faire cela. Par exemple, le module statistics contient la fonction mean.
>>> from statistics import mean
>>> liste = [1,3,5,2,4]
>>> mean(liste)
3.0
4 - Interaction entre Python et un tableur
Ce que nous venons de faire n'a rien d'extraordinaire. Les tableurs peuvent faire la même chose sans aucun problème. La force de Python vient surtout de ce qu'on peut faire en plus : gérer les données avec un code, en mettre certaines de côté, faire des interfaces, ect ...
Or, il existe un moyen simple de faire communiquer votre tableur préféré et votre programme Python. Il existe un format particulier de fichier texte, prévu pour enregistrer les données des tableurs en suivant une codification simple :
Dans un fichier csv, les données d'une ligne sont écrites sur une ligne unique et sont séparées par des points-virgules.
Csv veut dire comma-separated values.
A titre d'exemple, voici une copie d'écran d'un tableur contenant les données issues d'une acquisition vidéo visualisant une voiture en mouvement : on a le temps correspondant à l'image, la position horizontale x et la position verticale y de la voiture.
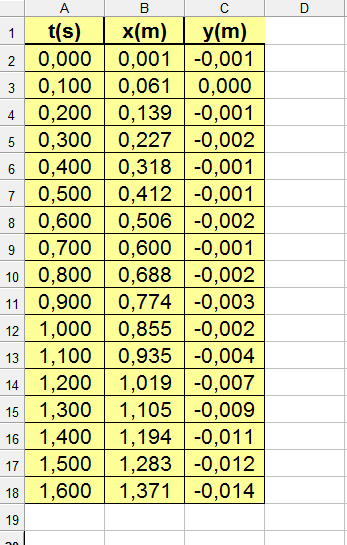
En faisant ENREGISTRER SOUS et en sélectionnant csv, vous allez obtenir un fichier texte que vous pourrez ouvrir avec le tableur, avec un lecteur de fichier texte basique ou Notepad++ par exemple. Que contient-il ? Ceci :
t(s);x(m);y(m)
0,000;0,001;-0,001
0,100;0,061;0,000
0,200;0,139;-0,001
0,300;0,227;-0,002
0,400;0,318;-0,001
0,500;0,412;-0,001
0,600;0,506;-0,002
0,700;0,600;-0,001
0,800;0,688;-0,002
0,900;0,774;-0,003
1,000;0,855;-0,002
1,100;0,935;-0,004
1,200;1,019;-0,007
1,300;1,105;-0,009
1,400;1,194;-0,011
1,500;1,283;-0,012
1,600;1,371;-0,014
Comme on peut le voir chaque ligne du tableur correspond à une ligne du fichier texte. Et chaque donnée-colonne est séparée des autres par un point-virgule.
| t(s) | x(m) | y(m) |
| 0,000 | 0,001 | -0,001 |
| 0,100 | 0,061 | 0,000 |
| 0,200 | 0,139 | -0,001 |
| 0,300 | 0,227 | -0,002 |
| 0,400 | 0,318 | -0,001 |
| 0,500 | 0,412 | -0,001 |
| 0,600 | 0,506 | -0,002 |
| 0,700 | 0,600 | -0,001 |
| 0,800 | 0,688 | -0,002 |
05° Créer des données dans le tableur que vous voulez. Les données seront bien présentées en colonne comme dans l'exemple présenté. La première ligne doit contenir les intitulés des données placées en dessous. Enregister les données en csv sous le nom "essai_csv.csv".
Bien, nous avons réussi à créer un fichier csv avec le tableur. Comment parvenir à récupérer les données de "essai_csv.csv" dans Python ?
C'est un fichier texte. On peut donc y accéder avec des méthodes bien nommées :
- open est une méthode-constructeur qui permet de créer dans Python un objet qui nous permettra d'interagir avec le fichier enregistré.
- readline permet de lire la ligne suivante dans le fichier. Une fois lu, un pointeur permettra de passer à la suivante.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
obj_fichier = open("essai_csv.csv","r",encoding='utf-8')
while 1 : # La condition est donc toujours True
ligne = obj_fichier.readline() # On tente de lire la ligne
if not(ligne) : # Si ligne n'existe pas, elle contient False
break # On sort de la boucle
else: # Sinon, c'est que ligne contient quelque chose
print(ligne, end='') # Pour supprimer le passage à la ligne automatique
obj_fichier.close()
input("Appuyez sur ENTREE")
obj_fichier = open("essai_csv.csv","r",encoding='utf-8')
Cette ligne permet de créer la variable obj_fichier qui contient l'objet-fichier permettant d'interagir avec le fichier "essai_csv.csv".
On notera qu'on utilise "r" pour indiquer qu'on l'ouvre uniquement en lecture.
while 1 : # La condition est donc toujours True
Avec Python, tout ce qui n'est pas 0 ou False est considéré comme True, 1 est toujours vrai. On crée donc une boucle infinie. On en sortira en utilisant un break.
ligne = obj_fichier.readline() # On tente de lire la ligne
On lit la ligne suivante de notre fichier.
if not(ligne) : # Si ligne n'existe pas, elle contient False
break # On sort de la boucle
Si la variable ligne ne contient rien, elle renvoit False. Comme on place le !, cela inverse la condition : on rentre donc dans la condition si on ne parvient pas à récupérer une ligne : break fait alors sortir de la boucle while.
else: # Sinon, c'est que ligne contient quelque chose
print(ligne, end='') # Pour supprimer le passage à la ligne automatique
Si la ligne existe, on l'affiche sur la console. Le code end='' permet de remplacer le passage à la ligne à la fin du print par ... rien.
obj_fichier.close()
input("Appuyez sur ENTREE")
On ferme la liaison entre l'objet-fichier et le fichier physique.
06° Tester ce code pour vérifier qu'il fonctionne bien. Vous devriez afficher quelque chose du type :
t(s);x(m);y(m) 0;0,001;-0,001 0,1;0,061;0 0,2;0,139;-0,001 0,3;0,227;-0,002 0,4;0,318;-0,001 0,5;0,412;-0,001 0,6;0,506;-0,002 0,7;0,6;-0,001 0,8;0,688;-0,002 Appuyez sur ENTREE
07° Est-ce normal qu'on passe à la ligne ? Enlever temporairement end=''. Relancer. Conclusion.
t(s);x(m);y(m) 0;0,001;-0,001 0,1;0,061;0 0,2;0,139;-0,001 0,3;0,227;-0,002 0,4;0,318;-0,001 0,5;0,412;-0,001 0,6;0,506;-0,002 0,7;0,6;-0,001 0,8;0,688;-0,002 Appuyez sur ENTREE
...CORRECTION...
Lorsqu'on lit une ligne enregistrée dans le fichier, on récupère aussi le passage à la ligne, le caractère \n dans Python.
Bon, le désavantage de cette méthode est que si un problème survient lors de la lecture, le programme va planter et le fichier sera mal refermé. Et là, il est possible que les données soient perdues, corrompues.
Nous allons compliquer les choses en présentant la méthode usuelle : on associe un open avec un opérateur with. Cette méthode garantit la fermeture correcte des fichiers en cas d'erreurs.
Il s'agit donc de remplacer la première ligne par la seconde. Mais attention, le reste des instructions devra être décalé sous le with :
obj_fichier = open("essai_csv.csv","r",encoding='utf-8')
with open("essai_csv.csv","r",encoding='utf-8') as obj_fichier :
Le code complet donne :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
with open("essai_csv.csv","r",encoding='utf-8') as obj_fichier :
while 1 : # La condition est donc toujours True
ligne = obj_fichier.readline() # On tente de lire la ligne
if not(ligne) : # Si ligne n'existe pas, elle contient False
break # On sort de la boucle
else: # Sinon, c'est que ligne contient quelque chose
print(ligne, end='') # Pour supprimer le passage à la ligne automatique
obj_fichier.close()
input("Appuyez sur ENTREE")
08° Tester la version avec le with pour voir qu'il fournit la même chose tant que tout va bien.
Il nous reste à stocker les données pour pouvoir en faire quelque chose. Nous allons les stocker dans deux listes nommées t,x. Nous n'y stockerons que les valeurs, les intitulés de la première ligne seront stockés ailleurs. Les informations sur y ne seront pas importées dans notre programme pour vous montrer qu'on peut limiter l'importation aux données voulues (et puis la vidéo caractérise un déplacement à plat, alors bon...)
09° Lancer pour comprendre ce que fait le programme suivant. Il va surement falloir vous documenter rapidement avec quelques recherches rapides sur un moteur de recherche : "Python+replace", "Python+split"... :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
t = [] # Création d'une liste vide
x = [] # Création d'une liste vide
with open("essai_csv.csv","r",encoding='utf-8') as obj_fichier :
while 1 : # La condition est donc toujours True
ligne = obj_fichier.readline() # On tente de lire la ligne
if not(ligne) : # Si ligne n'existe pas, elle contient False
break # On sort de la boucle
else: # Sinon, c'est que ligne contient quelque chose
ligne.replace('\n','') # On supprime le passage à la ligne finale de chaque ligne
elements = ligne.split(';') # On crée une liste contenant les valeurs de chaque ligne
for element in elements :
print(element)
obj_fichier.close()
input("Appuyez sur ENTREE")
t(s) x(m) y(m) 0 0,001 -0,001 0,1 0,061 0 0,2 0,139 -0,001 0,3 0,227 -0,002 0,4 0,318 -0,001 0,5 0,412 -0,001 0,6 0,506 -0,002 0,7 0,6 -0,001 0,8 0,688 -0,002 Appuyez sur ENTREE
...CORRECTION...
ligne.replace('\n','')
ligne est un string. Cette méthode des strings replacepermet de remplacer les caractères '\n' par ''(rien). Cette ligne permet donc de supprimer le passage à la ligne codé directement dans la chaîne lue.
elements = ligne.split(';')
Cette méthode des strings split permet de créer une liste elements contenant les éléments qu'on a trouvé dans la ligne en utilisant le caractère ';' comme élément séparateur.
La ligne suivante avec le FOR permet donc de lire un à un les éléments contenus dans cette liste.
10° Voici la dernière étape : après être parvenu à lire le fichier csv, nous récupérons les intitulés de la première ligne et nous mettons le reste dans deux listes t et x :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
t = [] # Création d'une liste vide
x = [] # Création d'une liste vide
with open("essai_csv.csv","r",encoding='utf-8') as obj_fichier :
print("On affiche les listes contenant les lignes du .csv")
compteur = 0
while 1 : # La condition est donc toujours True
ligne = obj_fichier.readline() # On tente de lire la ligne
if not(ligne) : # Si ligne n'existe pas, elle contient False
break # On sort de la boucle
else: # Sinon, c'est que ligne contient quelque chose
ligne.replace('\n','') # On supprime le passage à la ligne finale de chaque ligne
elements = ligne.split(';') # On crée une liste contenant les valeurs de chaque ligne
print(elements)
if compteur == 0 :
grandeur_abscisse = elements[0]
grandeur_ordonnee = elements[1]
else:
t.append(elements[0])
x.append(elements[1])
compteur += 1
obj_fichier.close()
print("\nOn affiche la liste contenant les temps")
print(t)
print("\nOn affiche la liste contenant les positions")
print(x)
input("Appuyez sur ENTREE")
Avec mes données, cela donne :
On affiche les listes contenant les lignes du .csv
['t(s)', 'x(m)', 'y(m)\n']
['0,000', '0,001', '-0,001\n']
['0,100', '0,061', '0,000\n']
['0,200', '0,139', '-0,001\n']
['0,300', '0,227', '-0,002\n']
['0,400', '0,318', '-0,001\n']
['0,500', '0,412', '-0,001\n']
['0,600', '0,506', '-0,002\n']
['0,700', '0,600', '-0,001\n']
['0,800', '0,688', '-0,002\n']
['0,900', '0,774', '-0,003\n']
['1,000', '0,855', '-0,002\n']
['1,100', '0,935', '-0,004\n']
['1,200', '1,019', '-0,007\n']
['1,300', '1,105', '-0,009\n']
['1,400', '1,194', '-0,011\n']
['1,500', '1,283', '-0,012\n']
['1,600', '1,371', '-0,014\n']
On affiche la liste contenant les temps
['0,000', '0,100', '0,200', '0,300', '0,400', '0,500', '0,600', '0,700', '0,800', '0,900', '1,000', '1,100', '1,200', '1,300', '1,400', '1,500', '1,600']
On affiche la liste contenant les positions
['0,001', '0,061', '0,139', '0,227', '0,318', '0,412', '0,506', '0,600', '0,688', '0,774', '0,855', '0,935', '1,019', '1,105', '1,194', '1,283', '1,371']
Appuyez sur ENTREE
11° Que contiennent les variables grandeur_abscisse et grandeur_ordonnee ?
...CORRECTION...
grandeur_abscisse devrait contenir l'index 0 de la première ligne : 't(s)'.
grandeur_ordonnee devrait contenir l'index 1 de la première ligne : 'x(m)'.
5 - Mini-projet
Utilisons nos connaissances pour exploiter les données fournies par l'analyse de la position de la voiture.
12° Les données stockées dans les listes x et t sont des strings pour l'instant. Modifier le programme à l'aide de la fonction float(string) pour transformer les données en nombres réels.
...CORRECTION...
13° Afficher le graphique de la position en fonction du temps.
...CORRECTION...
Il nous reste à exploiter les données : nous allons tenter de trouver la vitesse instantanée.
Comment ? Et bien la vitesse v2 sur l'image 2 est égale à v2 = (x3-x1) / (t3-t1)
14° Calculer la vitesse sur les images possibles, c'est à dire celles où on dispose des valeurs précédentes et des valeurs suivantes en x et t.
...CORRECTION...
15° Tracer la vitesse en fonction du temps.
...CORRECTION...
16° Enregistrer le tout dans un nouveau fichier csv nommé "vitesse.csv" : il faudra utiliser l'indication donner ci-dessous :
Pour écrire dans un fichier, nous allons utiliser une méthode qui se nomme write.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
obj_fichier = open("mon_fichier.txt","w")
obj_fichier.write("-- Ouverture --")
obj_fichier.write("Première entrée.")
obj_fichier.write("Deuxième entrée.")
obj_fichier.write("Troisième entrée.")
obj_fichier.write("-- Fermeture --")
obj_fichier.close()
Par contre, il faudra utiliser ouvrir votre fichier avec "w" pour indiquer que vous voulez l'ouvrir en écriture, write en anglais. Cette ouverture devra être faite hors de la boucle while sinon vous allez en recréer un à chaque fois et le nouveau va écraser l'ancien.
Dernière remarque : il faudra utiliser write à chaque fois que vous parvenez à faire un calcul sur l'une des lignes par exemple.
...CORRECTION...
Nous voilà à la fin de cette activité. Vous pourrez aller voir le module csv par la suite. Nous verrons qu'on peut également utiliser des tableaux de données plutôt que des listes, à l'aide du module numpy.