Python 21 : Gestion de l'encodage des textes avec Python
Le prérequis à cette partie est ici :
Avoir en mémoire les chapitres sur les strings et les fichiers semblent également indispensable.
Nous verrons ensuite plus précisement ce qui se cache derrière les encodages et comment communiquer de façon efficace avec d'autres programmes ou interfaces.
Enfin, nous finirons par utiliser des algorithmes de cryptographie plus efficace que le ROT-13.
1 - Gestion de l'encodage (encoding) du fichier Python lui-même
Alors, quel est le rapport entre les fichiers et les encodages ? Et bien, c'est très simple : lorsque vous travaillez avec Python 3 sur des chaînes de caractères, vous travaillez en Unicode sans vous en rendre compte. Mais si vous enregistrez des textes dans un fichier ou si vous voulez les afficher sur une interface, il va falloir les encoder de façon à ce qu'ils prennent moins de place. On va donc en réalité enregistrer des nombres. Or, comme vous l'avez vu avec la fiche sur l'encodage, les nombres ne correspondent pas forçément aux mêmes caractères en fonction de la table d'encodage. Et donc votre fichier risque d'être mal décodé mal affiché ou mal interprété. Bref, votre programme ne va pas fonctionner correctement ou risque de planter.
Nous allons commencer par voir les erreurs typiques d'encodage qu'on peut faire avec un éditeur de texte comme Notepad++ et les fichiers .py.
01° Enregistrer le fichier encodage.py avec Notepad++. Pensez bien à notifier avec Notepad++ qui vous travaillez en UTF-8. Lancez le programme pour vérifier qu'il fonctionne bien.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
texte = input("Voilà votre entrée texte : tapez votre texte :")
print(texte)
input("Pause. Appuyer sur ENTREE")
Ca n'a l'air de rien comme ça, ça date de vos chapitres 1 et 2 sur Python. Mais, en réalité, c'est plus complexe qu'on ne le pense.
La première ligne n'est pas obligatoire : #!/usr/bin/env python : on précise en Linux le chemin de l'interpréteur à utiliser.
La deuxième ligne # -*- coding: utf-8 -*- précise à l'interpréteur Python que le créateur du programme a utilisé l'encodage Utf-8 pour enregistrer les lignes de code. Si vous ne précisez pas cette information, Python va travailler par défaut en Utf-8. C'est pour cela que je disais qu'elle n'est pas nécessaire ici : on encode en Uft-8 via Notepad++ si on pense à changer l'encodage (qui de base est ANSI). C'est encore moins nécessaire avec IDLE qui encode de base en UTF-8. Alors pourquoi la mettre ? Après tout, cela ne sert à rien. Et bien, cela peut servir si votre utilisateur utilise un interpréteur Python ancien, qui ne travaille pas de base avec Utf-8 : il lui ordonne de changer son tableau de décodage. Ou pour l'avenir : un utilisateur futur de Python 4 va peut-être avoir un autre système d'encodage que l'Utf-8.
En conclusion, soyez précis et prenez l'habitude de toujours placer sur l'une des deux premières lignes l'encodage utilisé pour enregistrer votre fichier de code.
Les autres lignes sont très basiques mais nous verrons bientôt qu'il va falloir faire attention à deux-trois petites choses avec les affichages consoles.
02° Avec Notepad++, utilisez le menu ENCODAGE pour convertir en ANSI. Sauvegardez et testez le programme. Pourquoi est-ce un échec à votre avis ?
Voici le schéma récapitulatif du transfert des caractères. En jaune, les programmes ou fichiers fonctionnant en ANSI, en bleu ceux utilisant UTF-8.
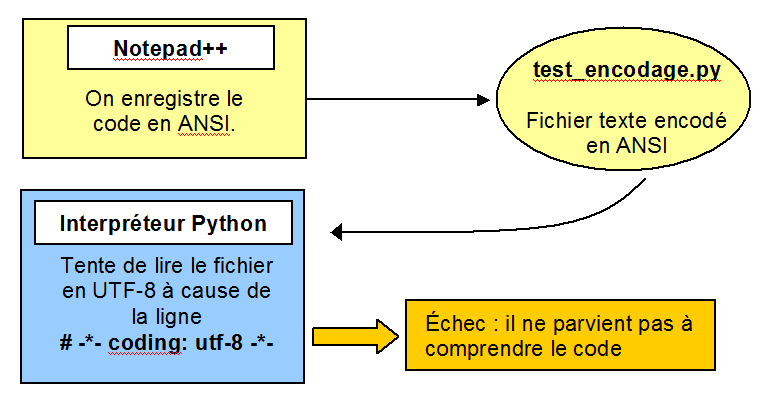
L'explication est simple : nous faison croire à l'interpréteur Python que le fichier .py est encodé en UTF-8 alors qu'il est en ANSI ! Comme il y a les caractères é et à, il ne parvient pas à obtenir un fichier correctement reconstruit et il plante.
Si tous les caractères étaient des caractères ASCII, cela ne provoquerait pas d'erreur car sur la plage 0-127, UTF-8 et ANSI sont comptatibles. C'est à partir des codes Unicode 128 et + que cela diverge : UTF-8 passe en mode 2 octets, vous vous souvenez ?
03° Remplacez # -*- coding: utf-8 -*- par # -*- coding: cp1252 -*-. Relancez. Ca fonctionne ? Oui ? Non ?
Chez moi, cela fonctionne. Souvenez-vous que ANSI n'est pas un terme officiel. Notepad++ utilise peut-être cp1252, iso-8859-1 ou cp850 chez vous. Tentez les autres si le premier ne fonctionne pas.
Voici le schéma récapitulatif du transfert des caractères. En jaune, les programmes ou fichiers fonctionnant en ANSI, en bleu ceux utilisant UTF-8.
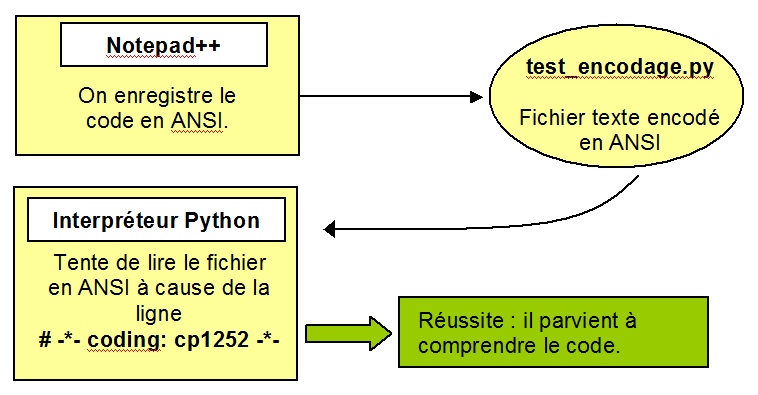
Première source d'erreur : communication entre le fichier texte du programme et l'interpréteur du langage : Pensez bien à toujours préciser l'encodage utilisé pour créer votre programme Python sur l'une des deux premières lignes. Cela évitera à l'interpréteur Python de faire n'importe quoi avec votre code. D'ailleurs, encoder toujours en UTF-8 si possible. Cet encodage est depuis quelques années l'encodage le plus utilisé et c'est l'encodage de base de Python. Vous ne devriez utiliser un autre encodage avec Notepad++ que dans des conditions particulières.
2 - Gestion de l'encodage entre Python et Console
On pourrait penser que c'est tout. Mais non. L'interpréteur Python communique avec d'autres logiciels. Par exemple, lorsque vous tapez un simple input ("Voilà votre entrée texte : tapez votre texte :") ou print(texte), il y a une communication entre l'interpréteur Python et la console utilisée. Il est donc préférable que la communication soit possible, non ?
De façon générale, Python est suffisamment bien conçu pour aller chercher l'information dont il a besoin tout seul. Mais allons regarder de plus prés néanmoins.
04° Avec Notepad++, créer le nouveau fichier-programme .py encodé en UTF-8. Ce programme va vous afficher l'encodage utilisé par votre console en entrée (à savoir quel encodage utilisé pour lui fournir de l'information textuelle) et en sortie (à savoir quel encodage elle utilise pour renvoyer de l'information textuelle). Utiliser le programme en cliquant directment dessus puis à travers l'IDLE de Python.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
print("Nom de l'encodage d'entrée vers la console (stdin) ")
print(sys.stdin.encoding)
print("Nom de l'encodage de sortie de la console (stdout) ")
print(sys.stdout.encoding)
input("Pause. Appuyer sur ENTREE")
Au moment où je lance ce programme, j'ai cp850 en entrée et sortie sur la console Python, et cp1252 avec la console de IDLE. voilà comment Python parvient à savoir comment communiquer avec telle ou telle application. Mais parfois, l'information n'est pas disponible de façon aussi facile. Il faut alors s'arranger pour savoir comment encoder et ensuite encoder correctement.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x8_ | Ç | ü | é | â | ä | à | å | ç | ê | ë | è | ï | î | ì | Ä | Å |
| 0x9_ | É | æ | Æ | ô | ö | ò | û | ù | ÿ | Ö | Ü | ø | £ | Ø | × | ƒ |
| 0xA_ | á | í | ó | ú | ñ | Ñ | ª | º | ¿ | ® | ¬ | ½ | ¼ | ¡ | « | » |
| 0xB_ | ░ | ▒ | ▓ | │ | ┤ | Á | Â | À | © | ╣ | ║ | ╗ | ╝ | ¢ | ¥ | ┐ |
| 0xC_ | └ | ┴ | ┬ | ├ | ─ | ┼ | ã | Ã | ╚ | ╔ | ╩ | ╦ | ╠ | ═ | ╬ | ¤ |
| 0xD_ | ð | Ð | Ê | Ë | È | ı | Í | Î | Ï | ┘ | ┌ | █ | ▄ | ¦ | Ì | ▀ |
| 0xE_ | Ó | ß | Ô | Ò | õ | Õ | µ | þ | Þ | Ú | Û | Ù | ý | Ý | ¯ | ´ |
| 0xF_ | ¤¤¤ | ± | ‗ | ¾ | ¶ | § | ÷ | ¸ | ° | ¨ | · | ¹ | ³ | ² | ■ | ¤¤¤ |
Allez, maintenant que je sais que Python encode mes strings en cp850 lorsqu'il les envoie vers la console, je vais créer un programme qui montre cette limitation : je vais tenter d'afficher un caractère que n'est pas sur la table d'encodage cp850 !
05° Avec Notepad++, créer le nouveau fichier-programme .py encodé en UTF-8. Ce programme provoque l'affichage sur la console de deux chaînes de caractères. Lancer le programme en cliquant dessus. Il devrait fonctionner avec la première qui ne contient que des caractères appartenant à cp850 et avoir du mal pour la seconde car je lui demande d'afficher des caractères qui ne sont pas dans la table d'encodage cp850.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print("Cette chaine devrait fonctionner même avec des à ou des é")
input("Pause. Appuyer sur ENTREE")
print("Par contre, avec les caractères monétaires ¥ ou €, c'est plus difficile.")
input("Pause. Appuyer sur ENTREE")
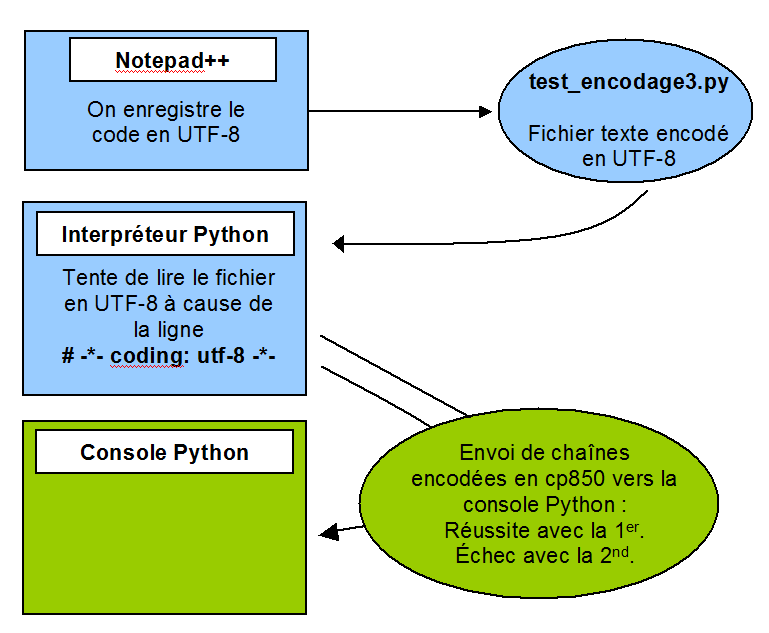
06° Sans modifier votre programme, lancez le via l'IDLE. Cette fois, ça devrait fonctionner puisque l'IDLE utilise cp1252 qui contient les deux symboles monétaires utilisés...
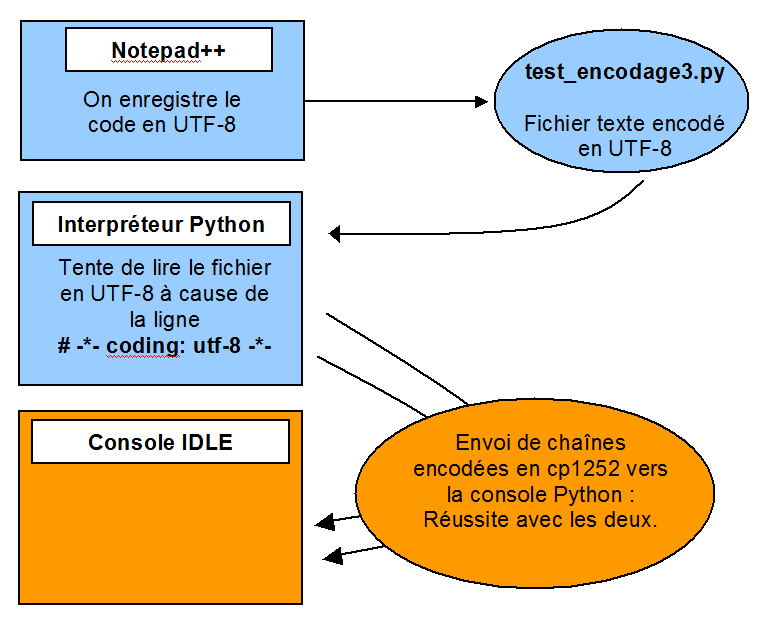
Deuxième source d'erreur : transfert de chaîne de caractères entre l'interpréteur et un autre programme : Il faut connaitre les encodages utilisés par les programmes qui communiquent avec le votre, sinon ça peut mal se passer. Nous allons voir qu'on peut forcer un encodage et gérer les caractères qui ne conviennent pas. C'est toujours mieux que de laisser le programme s'arrêter brutalement.
Maintenant que vous commencez à comprendre à quel point l'encodage peut être problématique lorsqu'on communique avec des interfaces utilisant de vieux encodages. Utf-8 devenant quasiment un classique, cela devient moins critique, du moins dans les pays utilisant les caractères latins en priorité.
Si vous voulez connaitre l'encodage que choisit Python en fonction de l'interface, vous pouvez également utiliser ce code :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import locale
print(locale.getpreferredencoding(False))
Une autre façon de faire consiste à ouvrir un fichier et à afficher les informations liées à cet objet-fichier :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
obj_fichier = open("mon_test.txt","w")
print(obj_fichier)
input("Pause. Appuyer sur ENTREE")
<_io.TextIOWrapper name='mon_test.txt' mode='w' encoding='cp1252'>
Appuyer sur ENTREE
3 - Encodage des Strings
Mais comment faire donc pour lire un vieux fichier texte encodé dans un autre format que uft-8 ? Nous allons rentrer dans le vif du sujet.
Tout d'abord, il faut comprendre que les chaines de caractères dans Python sont gérées en Unicode, sans encodage aucun. Les chaines de ce type sont ce qu'on nomme les str, les strings.
07° Ouvrir la console Python et taper les instructions pour voir leur execution en mode direct. Nous allons utiliser temporairement directement l'interface pour vous montrer le principe de l'encodage et du décodage des chaines de caractères.
>>> ma_chaine = "Alors, ça a fonctionné ou pas ?"
>>> type(ma_chaine)
<class 'str'>
Comme on le voit, ma_chaine est un objet de classe str. Il s'agit d'un ensemble de caractères codés par leur code Unicode.
Pour encoder un objet x de classe str, nous allons utiliser la méthode encode('nom_encodage'). Avec l'objet ma_chaine, on obtient un code du type : ma_chaine.encode('uft-8') ou ma_chaine.encode('latin1').
>>> mon_codage = ma_chaine.encode('latin1')
>>> mon_codage
b'Alors, \xe7a a fonctionn\xe9 ou pas ?'
>>> type(mon_codage)
<class 'bytes'>
On voit que mon_codage n'est plus un str, c'est un bytes : si vous vous souvenez du chapitre ou de la fiche sur les différentes bases, cela veut dire "mot numérique" ou "octet" en français. Mais, alors, pourquoi afficher des caractères ? Et bien, c'est le choix fait par les créateurs de Python : pour les caractères ASCII imprimables, on les montre directement plutôt que d'afficher la valeur de l'octet. Pour les autres caractères par contre, on affiche \x suivi de la valeur de l'octet en hexadécimal. L'intérêt est de mettre en valeur les caractères non ascii ou non imprimables.
Observons la réponse obtenue avec print(mon_codage) : b indique qu'il ne s'agit pas d'un string mais d'une suite d'octets (bytes). On y trouve les octets codant A, l, o, r, s, , et . Après l'espace, on voit l'apparition d'un premier octet non ascii : le code hexadécimal E7, soit 15*16+7 = 247 en décimal. Une recherche sur la table latin-1 permet de retrouver le code du ç...
b'Alors, \xe7a a fonctionn\xe9 ou pas ?'
Pour rappel, voilà un bout de la table d'encodage latin1 :
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xD_ | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| 0xE_ | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| 0xF_ | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
08° Créer un mon_codage à partir de ma_chaine en utilisant la méthode encode avec l'argument 'utf-8'. Donner les valeurs des octets permettant d'encoder le ç et le é. Pour ces deux caractères, a-t-on un encodage un octet ou deux octet pour l'UTF-8 ? Du coup, le transfert est-il plus rapide en latin-1 ou en UTF-8 ? Est-ce si grave avec les capacités modernes de communication ?
Il n'empêche que ce n'est pas très clair. Les bytes sont des octets codant des nombres et on les affiche parfois comme des caractères. Bof bof. Si on veut mieux voir la nature totalement chiffrée de la chaîne de caractères encodée, voilà une méthode permettant d'obtenir les valeurs décimales des octets :
J'utilise encore le codage direct sur la console mais on peut également faire la même chose avec un programme. N'oubliez pas la tabulation après le for.
>>> mon_codage = ma_chaine.encode('utf-8')
>>> for octet in mon_codage:
print(octet, end="-")
65 - 108 - 111 - 114 - 115 - 44 - 32 - 195 - 167 - 97 - 32 - 97 - 32 - 102 - 111 - 110 - 99 - 116 - 105 - 111 - 110 - 110 - 195 - 169 - 32 - 111 - 117 - 32 - 112 - 97 - 115 - 32 - 63 -
>>> len(mon_codage)
33
On voit beaucoup mieux qu'on a en réalité créé une suite de nombre non ? D'ailleurs, la fonction len(mon_codage) permet de voir qu'il a fallu 33 octets pour encoder le texte.
Dans un programme enregistré, ça donnerait :
ma_chaine = "Alors, ça a fonctionné ou pas ?"
mon_codage = ma_chaine.encode('utf-8')
for octet in mon_codage :
print(octet, end="-")
len(mon_codage)
09° Refaire la même chose avec l'encodage utf-16 qui utilise de base deux octets par caractère à encoder. Quelle est la taille mémoire en octets ? Sur un fichier texte de la taille d'un livre, voyez-vous l'intérêt de l'utf-8 ?
10° Faire un programme qui demande à l'utilisateur de rentrer un string, un type d'encodage et qui va encoder ce string. Montrer le contenu des octets de l'encodage obtenu.
Et en binaire ?
Pour afficher les valeurs des octets en binaire, il faut utiliser print(bin(octet)).
Pour informer qu'il s'agit de nombre binaire, on a la notation 0b en préfixe de la valeur des bits. Attention avec cet affichage : les premiers bits à 0 ne sont pas affichés.
Ainsi le nombre 5 (en base 10) serait affiché 0b101 et pas 0b00000101.
>>> bin(5)
'0b101'
>>> type(bin(5))
<class 'str'>
Attention, on obtient bien un string ! Pourquoi ? Simplement car on pourra ainsi traiter les bits très simplement en fonction de leur position, à l'aide d'une boucle. Il faudra faire attention, le bit de point faible est à droite, pas à gauche...
Un petit truc que vous comprendrez plus tard pour inverser les caractères d'une chaîne de caractères :
>>> bin(23)
'0b10111'
>>> bin(23)[::-1]
'11101b0'
Si votre nombre est initialement en hexadécimal, il suffit de le préfixer avec 0x.
>>> bin(0xa7)
'0b10100111'
>>> type(bin(0xa7))
<class 'str'>
Si vous voulez traduire du binaire en base 10, c'est possible aussi. Il suffit de le préfixer par 0b :
>>> 0b101
5
Comme votre octet binaire risque d'être un string si vous avez suivi, on peut aussi utiliser ceci :
>>> int('101',2)
5
>>> int('0b101',2)
5
Le 2 indique que '101' ou '0b101' est à décoder comme étant un nombre exprimé en base 2.
Et l'hexadécimal ?
Pour l'hexadécimal, c'est pareil mais la fonction pour obtenir un string correspondant au nombre exprimé en base 16 est hex(nombre).
En version condensée :
>>> hex(240)
'0xf0'
>>> hex(245)
'0xf5'
>>> type(hex(245))
>>> hex(245)[::-1]
'5fx0'
>>> hex(0b111011101)
'0x1dd'
>>> int('0x1dd',16)
477
Bon. Faisons un petit bilan, car nous avons vu beaucoup de choses dernièrement. Vous savez maintenant comment :
- Enregistrer des caractères dans un fichier.
- Lire les caractères enregistrés dans un fichier
- Encoder un string dans différents encodages et obtenir la valeur des octets d'encodage
Il nous reste donc à voir comment faire l'opération inverse : comment transformer une suite de nombres encodés en une belle chaîne de caractères ?
Facile. On n'utilise pas x.encode('type_encodage') mais x.decode('type_encodage'). Attention, cette fois, x devra être de classe bytes, pas un str. Pour une fois, vous ne pourrez pas dire que les concepteurs de Python n'ont pas été sympas avec vous ! Attention, pas de è sur decode, ça reste de l'anglais.
11° Réaliser un programme qui stocke dans mon_encodage le string "Martine écrit en Utf-8" en Utf-8 puis que décode mon_encodage en latin-1. Observez le résultat final.
Pour finir, le programme suivant va demander un texte à l'utilisateur, ainsi qu'un type d'encodage puis un type de décodage. Il encode le string et montre les valeurs des octets stockés puis décode les octets en respectant les règles du second type d'encodage. Il tente alors de restituer le résultat du décodage à l'écran.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
mon_texte = input("Donnez le texte que vous voulez encoder puis decoder : ")
encodage_1 = input("Avec quel encodage voulez-vous encoder votre texte ? : ")
encodage_2 = input("Avec quel encodage voulez-vous décoder votre texte ? : ")
print("\nVous voulez encoder le texte suivant : " + mon_texte)
print("Sa classe est : ")
print(type(mon_texte))
# A partir d'ici, on encode
mon_encodage = mon_texte.encode(encodage_1)
print("\nVous avez demandé l'encodage de mon_texte à l'aide de " + encodage_1)
print("Le résultat est de la classe suivante : ")
print(type(mon_encodage))
print("Voilà les valeurs des octets obtenus : ")
for octet in mon_encodage :
print(octet, end='-')
# A partir d'ici, on tente de décoder
mon_decodage = mon_encodage.decode(encodage_2)
print("\n\nVous avez ensuite voulu décoder ceci avec l'encodage " + encodage_2)
print("Le résultat est de la classe suivante : ")
print(type(mon_decodage))
print("Si le résultat est interprétable, cela donne ")
print(mon_decodage)
input("Pause. Appuyer sur ENTREE")
12° Tentez d'autres string dans le sens encodage en utf-8 et décodage en latin-1. Bon, et si vous encodiez en latin-1 et tentiez de décoder en pensant que c'était de l'Utf-8 ? Et oui : ça plante. Utf-8 ne trouve pas des suites d'octets correspondants à sa norme (c'est normal, le texte est encodé en latin-1...). Mais alors, ça peut provoquer la fin d'Internet cette histoire ? Non, il y a moyen de ne pas tenir compte des erreurs détectées lors de l'encodage comme lors du décodage.
Pour remplacer les caractères non chiffrables (hors table d'encodage) ou indéchiffrables, il faut utiliser par exemple encode('utf-8', 'replace') si vous encodez, ou decode('utf-8', 'replace') si vous décodez. Cela remplace les erreurs d'encodage par le caractère �. Si vous travaillez sur une console en cp850 ou moins, oubliez : elle ne sera pas non plus afficher ceci.
13° Utiliser l'attribut 'replace' mais passer par l'IDLE, sinon je ne suis pas certain que cela fonctionne (voir ma remarque sur l'absence du caractère dans une console en encodage cp850).
Et si on a affaire à un programme console ? On fait comment ? Et bien, on peut utiliser 'backslashreplace' qui va remplacer le code défectueux par sa valeur précédée d'un backslash \. C'est mieux que rien. Faites le test, ça fonctionne cette fois même avec les vielles consoles. Vous devriez voir que le code posant problème est un simple è, le code \xe9 s'affichant sur la console.
Dernière méthode : on utilise 'ignore' : on ne tente pas d'afficher quoi que ce soit pour cet octet. On l'ignore dignement.
Et finalement, comment connaitre les encodages disponibles pour votre interpréteur Python ?
import sys
import encodings
print("Liste des encodages disponibles")
print (''.join('- ' + e + '\n' for e in sorted(set(encodings.aliases.aliases.values()))))
print('pause')
D'ailleurs, pour avoir une autre version de la gestion des encodings, vous pouvez aller là-bas. Sam & Max. C'est instructif.
Chez moi, j'obtiens la liste suivante :
- ascii
- base64_codec
- big5
- big5hkscs
- bz2_codec
- cp037
- cp1026
- cp1125
- cp1140
- cp1250
- cp1251
- cp1252
- cp1253
- cp1254
- cp1255
- cp1256
- cp1257
- cp1258
- cp273
- cp424
- cp437
- cp500
- cp775
- cp850
- cp852
- cp855
- cp857
- cp858
- cp860
- cp861
- cp862
- cp863
- cp864
- cp865
- cp866
- cp869
- cp932
- cp949
- cp950
- euc_jis_2004
- euc_jisx0213
- euc_jp
- euc_kr
- gb18030
- gb2312
- gbk
- hex_codec
- hp_roman8
- hz
- iso2022_jp
- iso2022_jp_1
- iso2022_jp_2
- iso2022_jp_2004
- iso2022_jp_3
- iso2022_jp_ext
- iso2022_kr
- iso8859_10
- iso8859_11
- iso8859_13
- iso8859_14
- iso8859_15
- iso8859_16
- iso8859_2
- iso8859_3
- iso8859_4
- iso8859_5
- iso8859_6
- iso8859_7
- iso8859_8
- iso8859_9
- johab
- koi8_r
- kz1048
- latin_1
- mac_cyrillic
- mac_greek
- mac_iceland
- mac_latin2
- mac_roman
- mac_turkish
- mbcs
- ptcp154
- quopri_codec
- rot_13
- shift_jis
- shift_jis_2004
- shift_jisx0213
- tactis
- tis_620
- utf_16
- utf_16_be
- utf_16_le
- utf_32
- utf_32_be
- utf_32_le
- utf_7
- utf_8
- uu_codec
- zlib_codec
4 - Visualisation de l'encodage des fichiers avec Notepad++
Là, ça va aller vite : nous allons voir comment enregistrer un fichier texte avec l'encodage voulu et comment lire le contenu d'un fichier texte en le décodant à l'aide d'un encodage qu'on suppose être le bon... Et c'est là tout le problème : si vous n'avez aucune idée de l'encodage d'un fichier texte inconnu, le risque est grand qu'il fasse planter votre beau programme.
Commençons par préciser qu'un fichier n'est qu'un ensemble d'octets : sur le disque dur, le fichier-texte est une suite de nombre compris entre 0 et 255.
Regardons ça avec Notepad++ :
14° Créer une nouveau fichier avec Notepad++, encodé en ANSI (menu encodage) et contenant la ligne suivante qui contient 36 caractères :
Voilà quelques ç à et autres # ou @.
15° Sélectionner tous les caractères de votre texte puis aller dans le menu Compléments>Converter>ASCII-->HEX. Vous devriez obtenir la liste des octets à utiliser pour stocker cette ligne en ANSI.
566F696CE0207175656C7175657320E7
20E0206574206175747265732023206F
7520402E
On voit qu'on obtient par ligne, 16 octets exprimés en hexadécimal. 56 en hexa correspond bien à V par exemple.
On a donc 16+16+4, 36 octets pour encoder la ligne en "ANSI". C'est normal, c'est un encodage sur 1 octet par caractère.
16° Modifier le premier 56 en 57 et faire la transformation inverse HEX vers ASCII.
Woilà quelques ç à et autres # ou @.
Vous savez convertir des encodages de fichiers à travers Notepad++ et constater qu'on stocke bien des octets et pas des caractères.
Vous savez convertir des chaînes de caractères à l'aide de Python.
Il faut maintenant voir comment dire à Python d'enregistrer ou lire un fichier en latin-1, en utf-8 ou un autre encodage.
5 - Encodage des fichiers à l'aide de Python
Pour décoder les octets (bytes) d'un string, nous avons vu la méthode decode pour laquelle on doit préciser le type d'encodage utilisé.
Pour encoder un string en octets, nous avons vu la méthode encode pour laquelle on doit préciser le type d'encodage utilisé.
Nous avons vu les méthodes read et write qui s'appliquent aux objets-fichiers. Ce n'est pas directement dans le read ou write qu'on précise l'encodage. Pourquoi ? Pour qu'on ne puisse pas utiliser un bout de fichier en latin_1 et le bout suivant en utf-8 par exemple. L'ensemble d'un fichier doit utiliser le même encodage, sinon c'est ingérable. Vous imaginez un livre où on change de langue à chaque ligne ?
C'est donc lors de l'ouverture du fichier avec la fonction-constructeur open qu'on va indiquer l'encodage à utiliser pour lire les octets du fichier ou pour y placer des octets.
Depuis le chapitre sur les fichiers, vous avez utilisé la méthode de cette façon par exemple : obj_fichier = open("mon_fichier.txt","r"). On n'y précise donc aucun encodage. Pourquoi ça fonctionne alors ? C'est simple : si vous ne donnez aucune indication d'encodage lors de l'ouverture du fichier, c'est l'interpréteur qui va choisir l'encodage. Souvent l'UTF-8. Mais travailler dans le brouillard et laisser la machine faire le boulot dans son coin risque à terme de créer une erreur.
Or, on peut préciser l'encodage d'un fichier lors de son ouverture avec open. Il suffit de rajouter un argument encoding.
Ainsi obj_fichier = open("mon_test.txt","w", encoding="latin_1") va ouvrir un fichier en écriture(w) et en y encodant les caractères en latin-1. Chaque caractère possède donc un octet uniquement.
Ainsi obj_fichier = open("mon_test.txt","r", encoding="utf_8") va ouvrir un fichier en lecture(r) et en y décodant les octets des caractères à l'aide de l'utf-8. Chaque caractère peut donc être codé sur un octet ou plus.
Pour vous montrer que cela marche, nous allons utiliser un programme qui va créer un fichier dans un type d'encodage, le fermer, le lire avec le bon encodage puis le relire avec un autre encodage.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
encodage_ecriture = "latin_1"
encodage_lecture = "iso8859_2"
#################################
# PARTIE 1 CREATION
#################################
print("-- CREATION D'UN FICHIER encodé en ",encodage_ecriture)
obj_fichier = open("mon_test.txt","w", encoding=encodage_ecriture)
obj_fichier.write("Debut")
for i in range (180,191):
if chr(i).isprintable():
obj_fichier.write("Numéro "+str(i)+" : "+ chr(i)+"\n")
obj_fichier.write("Fin")
obj_fichier.close()
input("Appuyer sur ENTREE")
#################################
# PARTIE 2 LECTURE CORRECTE
#################################
print("-- LECTURE DU FICHIER qu'on suppose encodé en ", encodage_ecriture)
obj_fichier = open("mon_test.txt","r", encoding=encodage_ecriture)
print(obj_fichier.read())
obj_fichier.close()
input("Appuyer sur ENTREE")
#################################
# PARTIE 3 LECTURE AVEC UN AUTRE ENCODAGE
#################################
print("-- LECTURE DU FICHIER qu'on suppose encodé en ", encodage_lecture)
obj_fichier = open("mon_test.txt","r", encoding=encodage_lecture)
print(obj_fichier.read())
obj_fichier.close()
input("Appuyer sur ENTREE")
17° Utiliser le programme en laissant les encodages latin_1 (Europe de l'Ouest) et cp850 (Europe centrale). Utiliser plutôt IDLE car votre console système ne pourra pas nécessairement afficher les caractères de ces encodages.
Normalement, on constate bien qu'on ne pourra pas lire les bons caractères avec le deuxième encodage. Mais ça ne provoque pas d'arrêt du programme. C'est l'équivalent du "Martine écrit en utf-8" que nous avons déjà vu.
18° Utilisez maintenant iso8859_2 (Europe centrale) comme encodage de lecture.
19° Utilisez maintenant iso8859_6 (Arabe) comme encodage de lecture.
Cette fois, ça ne fonctionne pas :
UnicodeDecodeError: 'charmap' codec can't decode byte 0xdc in position 18: character maps to <undefined>
Allons voir la table iso8859_6 pour voir d'où vient le problème :
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x08_ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ |
| 0x09_ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ | ¤¤¤ |
| 0xA_ | ¤¤¤ | � | � | � | ¤ | � | � | � | � | � | � | � | ، | ¤¤¤ | � | � |
| 0xB_ | � | � | � | � | � | � | � | � | � | � | � | ؛ | � | � | � | ؟ |
| 0xC_ | � | ء | آ | أ | ؤ | إ | ئ | ا | ب | ة | ت | ث | ج | ح | خ | د |
| 0xD_ | ذ | ر | ز | س | ش | ص | ض | ط | ظ | ع | غ | � | � | � | � | � |
| 0xE_ | ـ | ف | ق | ك | ل | م | ن | ه | و | ى | ي | ً | ٌ | ٍ | َ | ُ |
| 0xF_ | ِ | ّ | ْ | � | � | � | � | � | � | � | � | � | � | � | � | � |
Si vous allez voir la case 120 en décimal, DC en hexadécimal, noté 0xdc par Python : on voit que la case n'existe pas. Cet encodage n'utilise pas cette case. D'où le problème et l'erreur. Vous voyez donc que se tromper d'encodage peut créer autre chose qu'un mauvais affichage : cela peut faire planter le système.
20° Passons au pire : l'ouverture en utf-8 d'un fichier encodé par un encode 1 octet : dans ce cas, lors du décodage, Python va déclarer une erreur car les caractères UNICODE supérieurs à 127 sont codés sur plusieurs octets mais avec des valeurs particulières : ces octets codent également le nombre d'octets à lire pour ce caractère par exemple. Utiliser utf_8 en lecture pour le constater.
21° Inversez : utiliser utf_8 en écriture et latin_1 en lecture. On retrouve le fait que certains caractères utf-8 codés sur deux octets vont provoquer l'apparition de deux caractères à l'écran si on pense que le fichier texte est encodé dans un format 1 octet.
Conclusion : il est impératif de connaitre l'encodage d'un fichier que vous voulez lire, sinon ça peut provoquer l'arrêt de votre programme. Donc, penser également à toujours préciser l'encodage d'un fichier texte que vous avez enregistré vous-même.